
C言語のきほん|構造体配列とポインタ
構造体配列をポインタで扱えるようになると、繰り返し処理の見え方が一段深くなる。
構造体の変数をポインタで指す方法が分かってくると、次に気になってくるのが構造体の配列をポインタでどう扱うかという点です。
構造体が1個だけなら、ポインタはその1個を指すだけでした。けれど、構造体が配列になって並んでいるときは、ポインタを使って先頭から順番にたどっていけるようになります。
ここで大事なのは、構造体配列でも基本の考え方は普通の配列と同じだということです。
配列名は先頭要素のアドレスとして扱われるので、その先頭要素を指すポインタを用意すれば、ポインタ演算によって2番目、3番目の要素へ進めます。
そして、構造体配列をポインタで扱えるようになると、
- 配列の要素を順番に処理する仕組みがよく分かる
- 添字を使う書き方とポインタ演算の対応が見えてくる
- 関数へ構造体配列を渡すときの理解が深まる
- 配列とポインタの関係をより実践的に捉えられる
といったメリットがあります。
最初は、persons[i].name と (p + i)->name や p->name の違いが少しややこしく感じるかもしれません。
でも、落ち着いて見ると、やっていることは「どの要素を指しているか」が違うだけです。
ここでは、構造体配列をポインタで指す基本、ポインタ演算によるアクセス、ポインタ自体を進める方法まで、順番にやさしく見ていきましょう。
構造体配列をポインタで指すとは何か
構造体の配列は、同じ型の構造体がメモリ上に連続して並んでいるものです。
たとえば、Student 型の配列があれば、1件目、2件目、3件目の学生情報が順番に並んで保存されています。
このとき、配列名は先頭要素のアドレスとして扱われるので、たとえば
studentsは、次のものと同じ場所を表します。
&students[0]つまり、構造体配列の先頭を指すポインタは、次のように書けます。
Student *p = students;これは、
Student *p = &students[0];と同じ意味です。
ここが、構造体配列とポインタの出発点です。
なぜ構造体配列をポインタで扱うのか
構造体配列をポインタで扱う理由は、単に別の書き方を覚えるためではありません。
ポインタを使うと、配列の各要素をより低いレベルの仕組みとして理解できるようになります。
たとえば、配列の添字を使う書き方では、
students[i].idと書きます。
一方、ポインタを使うと、
(p + i)->idと書けます。
この2つは同じ意味です。
つまり、配列の添字という見やすい書き方の裏で、実際にはポインタ演算に近いことが行われていると理解できるようになります。
配列名と先頭アドレスの関係を整理する
ここはとても重要なので、表で整理しておきます。
| 書き方 | 意味 |
|---|---|
| students | 配列の先頭要素のアドレス |
| &students[0] | 先頭要素のアドレス |
| Student *p = students; | p が先頭要素を指す |
| Student *p = &students[0]; | 上と同じ |
この関係は、int 配列でも double 配列でも同じでした。
構造体配列でも、基本はまったく同じです。
サンプルプログラムで確認する
図書情報を例にして説明します。
ファイル名:15_9_1.c
#include <stdio.h>
// 図書情報を表す構造体
typedef struct {
int no; // 番号
char title[20]; // 書名
} Book;
int main(void)
{
Book books[3] = {
{1, "C言語入門"},
{2, "配列の基本"},
{3, "ポインタ講座"}
};
// 配列の先頭要素を指すポインタ
Book *p = books;
// (p + i) の形で表示
for (int i = 0; i < 3; i++) {
printf("%d %s\t", (p + i)->no, (p + i)->title);
}
printf("\n");
// ポインタ自体を進めながら表示
for (int i = 0; i < 3; i++) {
printf("%d %s\t", p->no, p->title);
p++;
}
return 0;
}実行結果例
1 C言語入門 2 配列の基本 3 ポインタ講座
1 C言語入門 2 配列の基本 3 ポインタ講座このプログラムでは、同じ配列の内容を2通りのポインタ操作で表示しています。
最初の for 文の意味
最初の for 文では、次の書き方を使っています。
(p + i)->no
(p + i)->titleここでの p は先頭要素を指しています。
そのため、
- p + 0 は 0番目の要素
- p + 1 は 1番目の要素
- p + 2 は 2番目の要素
を指します。
つまり、(p + i) は「i 番目の要素を指すポインタ」になります。
そして、その先の構造体メンバへ -> でアクセスしています。
添字との対応
| 添字を使う書き方 | ポインタを使う書き方 |
|---|---|
| books[i].no | (p + i)->no |
| books[i].title | (p + i)->title |
この対応が見えるようになると、構造体配列とポインタの関係がかなり分かりやすくなります。
2つ目の for 文の意味
2つ目の for 文では、少し違う書き方をしています。
printf("%d %s\t", p->no, p->title);
p++;ここでは、毎回 p 自体を次の要素へ進めています。
最初は p が books[0] を指しています。
1回表示したら p++ で次へ進むので、次は books[1] を指します。
さらに進めると books[2] を指します。
つまり、この書き方では、
- ポインタを固定して添字のようにずらす
- それともポインタ自体を進める
という2つの考え方のうち、後者を使っています。
2つの書き方の違いを整理する
| 書き方 | 特徴 |
|---|---|
| (p + i)->member | p は動かさず、i で位置を変える |
| p->member と p++ | p 自体を次の要素へ進める |
どちらも正しいです。
学習の初期段階では、(p + i)->member の方が「何番目の要素を見ているのか」が分かりやすいことがあります。
一方で、p++ を使う書き方は、ポインタそのものの動きを理解するのに向いています。
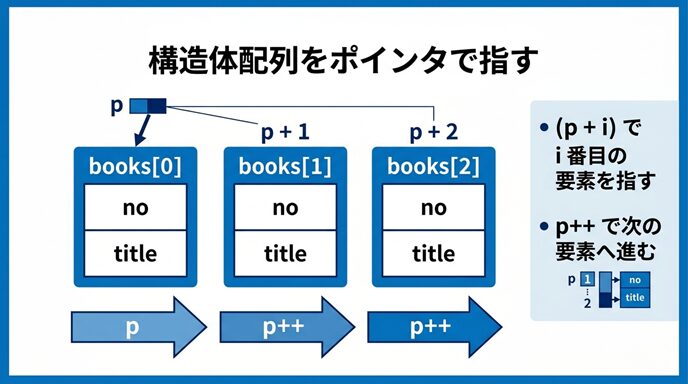
この図では、構造体配列 books の先頭要素を p が指している様子を表しています。
そこから p + 1、p + 2 と進むことで、次の要素を順に指せることが分かります。
また、p++ を使うと、ポインタそのものが次の構造体要素へ移動することも、あわせて理解しやすくなります。
(p + i)->member の読み方
この書き方は、最初は少し長く感じるかもしれません。
でも、意味を分けて考えると難しくありません。
(p + i)->noは、次の流れです。
- p は配列の先頭を指している
- p + i で i 番目の要素を指す
- ->no で、その構造体の no メンバにアクセスする
つまり、「i 番目の構造体の no」を見ているわけです。
これは配列の添字で書く
books[i].noと同じ意味です。
p++ で何が起こるのか
構造体配列で p++ を行うと、1バイトだけ進むわけではありません。
構造体1個分の大きさだけ進みます。
たとえば、Book 型の大きさが 24 バイトだったとすると、p++ すると 24 バイト先の次の要素を指すことになります。
これは int ポインタで p++ すると int 1個分進むのと同じ考え方です。
つまり、ポインタ演算は「バイト単位で適当に進む」のではなく、その型の大きさに応じて進むのです。
構造体配列とポインタの関係をさらに整理する
| 式 | 意味 |
|---|---|
| p | 先頭要素を指す |
| p + 1 | 次の要素を指す |
| p + i | i 番目の要素を指す |
| (*p).no | p が指す構造体の no |
| p->no | 上と同じ |
| (p + i)->title | i 番目の構造体の title |
この表を見ながらコードを読むと、かなり整理しやすくなります。
添字を使う方法とポインタを使う方法の違い
実際のプログラムでは、構造体配列を扱うときに添字を使うことも多いです。
たとえば、
for (int i = 0; i < 3; i++) {
printf("%d %s\n", books[i].no, books[i].title);
}のように書く方法です。
これはとても分かりやすいですし、初心者には特に読みやすいです。
一方で、ポインタを使う方法は、配列の正体やメモリの並びを意識しやすいという強みがあります。
比較表
| 方法 | 書きやすさ | 仕組みの見えやすさ |
|---|---|---|
| 添字 | 分かりやすい | やや抽象的 |
| ポインタ | 少し慣れが必要 | 低レベルの動きが見えやすい |
どちらが絶対によいということではなく、両方を理解しておくことが大切です。
配列の先頭を指すポインタを別の変数で保持する意味
配列名そのものも先頭要素を表せるのに、なぜわざわざ
Book *p = books;のようなポインタ変数を作るのでしょうか。
理由は、ポインタ変数なら動かせるからです。
配列名 books は、先頭を表す存在として使えますが、books++ のように増やすことはできません。
一方で、ポインタ変数 p なら p++ と書いて次の要素へ進めます。
この違いはとても大きいです。
| 対象 | 次の要素へ進めるか |
|---|---|
| 配列名 books | 進めない |
| ポインタ変数 p | 進める |
文字列メンバがあっても考え方は同じ
構造体のメンバに char 型配列が含まれていても、構造体配列をポインタで指す考え方は変わりません。
たとえば、
(p + i)->titleは、i 番目の構造体の title メンバを表します。
title が文字列配列だからといって、構造体要素の位置をたどる部分の考え方はそのままです。
違うのは、その先で文字列として表示したり strcpy で扱ったりする点だけです。
実践問題
次の要件を満たすプログラムを作成してください。
① 商品情報を表す構造体 Product を定義する。
メンバは、商品番号 no と商品名 name と価格 price とする。
② Product 型の配列に3件分のデータを初期化する。
③ 配列の先頭要素を指すポインタを用意する。
④ (p + i)->member の形を使って、全商品情報を表示する。
解答例
ファイル名:15_9_2.c
#include <stdio.h>
typedef struct {
int no;
char name[20];
double price;
} Product;
int main(void)
{
Product products[3] = {
{1, "ノート", 120.0},
{2, "ペン", 80.0},
{3, "消しゴム", 60.0}
};
Product *p = products;
for (int i = 0; i < 3; i++) {
printf("%d %s %.1f円\n",
(p + i)->no,
(p + i)->name,
(p + i)->price);
}
return 0;
}実行結果例
1 ノート 120.0円
2 ペン 80.0円
3 消しゴム 60.0円解説
この問題では、配列の先頭を指すポインタ p を使って、(p + i) の形で各要素を参照しています。
(p + i)->no は products[i].no と同じ意味です。
添字とポインタ演算の対応を確認するのにぴったりな問題です。
実践問題
次の要件を満たすプログラムを作成してください。
① 学生情報を表す構造体 Student を定義する。
メンバは、番号 no と氏名 name と点数 score とする。
② 4人分のデータを構造体配列に初期化する。
③ 配列の先頭を指すポインタを用意する。
④ p->member を使って表示し、各回ごとに p++ で次の要素へ進める。
⑤ 実践問題の氏名は、元の例とは別の名前にする。
解答例
ファイル名:15_9_3.c
#include <stdio.h>
typedef struct {
int no;
char name[20];
int score;
} Student;
int main(void)
{
Student students[4] = {
{1, "石田 恒一", 78},
{2, "上村 拓海", 85},
{3, "大西 翔太", 91},
{4, "川本 恒一", 88}
};
Student *p = students;
for (int i = 0; i < 4; i++) {
printf("%d %s %d点\n", p->no, p->name, p->score);
p++;
}
return 0;
}実行結果例
1 石田 恒一 78点
2 上村 拓海 85点
3 大西 翔太 91点
4 川本 恒一 88点解説
この問題では、最初に p が students[0] を指しています。
表示するたびに p++ しているので、次は students[1]、その次は students[2] というように進んでいきます。
ポインタ自体を動かしながら配列を順番に処理する基本を確認できます。
実践問題
次の要件を満たすプログラムを作成してください。
① 書籍情報を表す構造体 Book を定義する。
メンバは、番号 no、書名 title、ページ数 pages とする。
② 5冊分のデータを構造体配列に初期化する。
③ 配列の先頭要素を指すポインタを使って、最もページ数の多い書籍を探す。
④ 結果を表示する。
解答例
ファイル名:15_9_4.c
#include <stdio.h>
typedef struct {
int no;
char title[30];
int pages;
} Book;
int main(void)
{
Book books[5] = {
{1, "C言語入門", 220},
{2, "ポインタ解説", 180},
{3, "構造体の基本", 250},
{4, "配列演習", 160},
{5, "関数のしくみ", 210}
};
Book *p = books;
int max_index = 0;
for (int i = 1; i < 5; i++) {
if ((p + i)->pages > (p + max_index)->pages) {
max_index = i;
}
}
printf("最もページ数の多い書籍\n");
printf("番号:%d\n", (p + max_index)->no);
printf("書名:%s\n", (p + max_index)->title);
printf("ページ数:%d\n", (p + max_index)->pages);
return 0;
}実行結果例
最もページ数の多い書籍
番号:3
書名:構造体の基本
ページ数:250解説
この問題では、ポインタ p を基準にして、(p + i)->pages の形で各要素のページ数を比較しています。
構造体配列をポインタで扱うと、検索のような処理もこのように書けるようになります。
実践問題
次の要件を満たすプログラムを作成してください。
① 成績情報を表す構造体 Result を定義する。
メンバは、番号 no、氏名 name、数学 math、英語 english、平均 average とする。
② 5人分のデータを構造体配列に初期化する。
③ 配列の先頭を指すポインタを用意する。
④ ポインタを使って average を計算して各要素に保存する。
⑤ average の高い順に並べ替えて表示する。
⑥ 氏名データは別の名前にする。
解答例
ファイル名:15_9_5.c
#include <stdio.h>
typedef struct {
int no;
char name[20];
int math;
int english;
double average;
} Result;
int main(void)
{
Result results[5] = {
{1, "坂井 颯太", 78, 84, 0.0},
{2, "中原 恒一", 91, 88, 0.0},
{3, "木下 悠真", 73, 80, 0.0},
{4, "藤田 拓真", 85, 90, 0.0},
{5, "西村 颯人", 88, 76, 0.0}
};
Result *p = results;
for (int i = 0; i < 5; i++) {
(p + i)->average = ((p + i)->math + (p + i)->english) / 2.0;
}
for (int i = 0; i < 4; i++) {
int max_index = i;
for (int j = i + 1; j < 5; j++) {
if ((p + j)->average > (p + max_index)->average) {
max_index = j;
}
}
if (max_index != i) {
Result temp = *(p + i);
*(p + i) = *(p + max_index);
*(p + max_index) = temp;
}
}
printf("平均点の高い順\n");
for (int i = 0; i < 5; i++) {
printf("%d %s 数学:%d 英語:%d 平均:%.1f\n",
(p + i)->no,
(p + i)->name,
(p + i)->math,
(p + i)->english,
(p + i)->average);
}
return 0;
}実行結果例
平均点の高い順
2 中原 恒一 数学:91 英語:88 平均:89.5
4 藤田 拓真 数学:85 英語:90 平均:87.5
5 西村 颯人 数学:88 英語:76 平均:82.0
1 坂井 颯太 数学:78 英語:84 平均:81.0
3 木下 悠真 数学:73 英語:80 平均:76.5解説
この問題では、配列全体を通してポインタ p を基準に使っています。
平均点の計算も比較も並べ替えも、すべて (p + i)->member の形で進めています。
また、要素の入れ替えでは構造体代入を使っているので、構造体を丸ごと交換できます。
構造体配列とポインタの理解が深まると、このような実用的な処理もかなり自然に書けるようになります。
よくある間違い
配列名をそのまま増やそうとしてしまう
books++;のような書き方はできません。
増やせるのはポインタ変数です。
そのため、必要なら
Book *p = books;
p++;のようにします。
p + i と *(p + i) の違いを混同する
- p + i は i 番目の要素を指すポインタ
- *(p + i) はそのポインタが指す構造体本体
です。
メンバへアクセスするときは、普通は
(p + i)->memberと書くと見やすいです。
p->member をそのまま繰り返して添字の代わりと思ってしまう
p を動かしていないなら、p->member はずっと先頭要素のままです。
2番目以降を見たいなら、p++ するか、(p + i)->member のように位置をずらす必要があります。
この記事で押さえておきたいポイント
| ポイント | 内容 |
|---|---|
| 配列名 | 先頭要素のアドレスとして扱われる |
| 先頭を指すポインタ | 構造体型 *p = 配列名; |
| i 番目の要素 | p + i |
| i 番目のメンバ | (p + i)->member |
| ポインタを進める | p++ |
| 添字との対応 | array[i].member と (p + i)->member は同じ意味 |
構造体配列とポインタの関係が見えてくると、配列の正体や繰り返し処理の仕組みがぐっと理解しやすくなります。
見た目は少し複雑でも、やっていることは「先頭を指して、必要な位置へ進み、その先のメンバを見る」というとても素直な流れです。
ここをしっかり押さえると、構造体とポインタの学習がさらに安定していきます。