
C言語のきほん|fprintfとfscanfによるファイル入出力
書いた形で保存し、決めた形で読み取る。fprintf と fscanf で広がるC言語のファイル活用。
これまでに、C言語では1文字ずつ扱う方法や、文字列をまとめて扱う方法を学んできました。そうした基本を押さえたうえで、次に覚えておきたいのが、書式付きでファイルに入出力する方法です。今回の中心になるのは、fprintf と fscanf です。これは、画面に表示する printf や、キーボードから読み取る scanf によく似ていますが、対象がファイルになる点が大きな違いです。
この2つを使えるようになると、ただデータを保存するだけでなく、整数・小数・文字列を決まった並びで整えて保存することや、その並びにしたがって正しく読み戻すことができるようになります。たとえば、名前と点数、商品名と価格、都市名と人口のように、複数種類のデータをひとまとまりで扱うときにとても便利です。元の資料でも、fprintf は書式付き出力、fscanf は書式付き入力として説明されており、あらかじめ決まったフォーマットのファイルを扱うときに有効だとされています。
ただし、便利な反面、fscanf は書式が合っていないと正しく読めないという特徴があります。そのため、使い方だけでなく、返却値を確認する習慣や、出力時と入力時で書式をそろえる意識もとても大切です。元の文書でも、fscanf は入力項目数を返し、期待した個数と一致するかどうかで成功判定を行うこと、また書式が合わないと読み込みに失敗しうることが強調されています。
ここでは、fprintf と fscanf の基本的な役割から、実際の流れ、つまずきやすい注意点、そして実践問題まで、やわらかく丁寧に見ていきましょう。なお、以下の解説は、ユーザーが提示した元文書の内容を土台に再構成したものです。
書式付きファイル入出力とは
書式付きファイル入出力とは、データを一定のルールで並べてファイルへ書き出し、その同じルールにしたがって読み戻す方法です。
たとえば、次のようなデータを考えてみます。
Tanaka 85 72.5この1行には、
- 名前
- 整数の点数
- 小数の平均値
のような複数の情報が入っています。
このようなデータは、ただ文字列として保存するのではなく、どの位置に何の種類の値があるのかを意識して扱うと便利です。そこで活躍するのが fprintf と fscanf です。
| 関数 | 役割 | 似ている標準入出力関数 |
|---|---|---|
| fprintf | 書式を指定してファイルへ出力する | printf |
| fscanf | 書式を指定してファイルから入力する | scanf |
つまり、printf と scanf のファイル版と考えると、とても理解しやすいです。元の資料でも、この対応関係がはっきり示されています。
fprintf関数とは
fprintf は、printf と同じように書式指定子を使いながら、出力先をファイルにできる関数です。関数宣言は次のとおりです。
#include <stdio.h>
int fprintf(FILE *restrict stream,
const char *restrict format, ...);この関数では、stream に出力先のファイルを指定し、format に %d や %f や %s などの書式指定子を含む文字列を書きます。元の資料では、fprintf は文字列、整数、浮動小数点数などを指定レイアウトでファイルへ直接書き込めるため、読みやすく整形されたデータ保存に向くと説明されています。
fprintfの返却値
fprintf は、出力に成功すると書き込んだ文字数を返し、エラーが起きると負の値を返します。
ふだんの学習ではそこまで細かく使わないこともありますが、重要なファイル出力では返却値を確認する考え方も大切です。これも元文書の説明に含まれている要点です。
fscanf関数とは
fscanf は、scanf と同じように書式を指定して、ファイルからデータを読み取る関数です。関数宣言は次のとおりです。
#include <stdio.h>
int fscanf(FILE *restrict stream,
const char *restrict format, ...);fscanf では、読み込み元のファイルを stream に指定し、format に従って入力データを分解し、それぞれの変数へ格納します。
たとえば、文字列、整数、小数を順番に読みたいときは、%s、%d、%lf などを使います。元の資料でも、fscanf は scanf と同様の変換を行い、指定したアドレスへ値を格納すると説明されています。
fscanfの返却値
fscanf は、成功した入力項目の個数を返します。
たとえば、3つの値を読むつもりで、実際に3つとも正しく読めたなら 3 が返ります。
照合の途中で失敗した場合は 0 になることもあり、変換がひとつも行われないまま入力エラーが起きた場合には EOF が返ります。これは元の資料の重要なポイントです。
この返却値を確認することで、「ちゃんと3項目読めたか」を判定できます。
そのため、fscanf を使うときは、返却値チェックが基本です。
fprintfとfscanfの関係
この2つの関数は、書く側と読む側で対になっています。
たとえば、fprintf で次のように書いたとします。
fprintf(fp, "%s %d %.1f\n", name, score, average);このとき、ファイルには「文字列 整数 小数」という並びで保存されます。
すると、読み込むときも同じ並びを前提にして、
fscanf(fp, "%49s %d %lf", in_name, &in_score, &in_average);のように読み取れます。
つまり、出力時の書式と入力時の書式は、対応している必要があるということです。元の文書でも、同じ書式に従って読み込むこと、期待する入力項目数を確認することが示されています。
書式付きファイル入出力の流れ
fprintf と fscanf を使うときも、大まかな流れはこれまでのファイル入出力と同じです。
- ファイルを開く
- fprintf で書く、または fscanf で読む
- 処理結果を確認する
- ファイルを閉じる
この流れを図でイメージすると、理解しやすくなります。
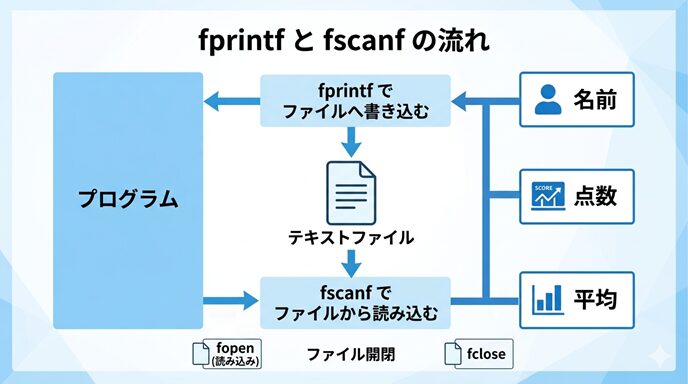
この図では、プログラムの中にある変数の値を fprintf でファイルに保存し、そのあと fscanf で再び変数へ戻す流れを表しています。
ここで大切なのは、ファイルがただの保存場所ではなく、決めた形式でデータを受け渡す中継地点になっていることです。
また、出力と入力のあいだで書式がずれてしまうと、読み込みが失敗することがあります。元の資料でも、たとえば「名前:福島太郎 年齢:20 身長:186.300000」のようにラベル付きで保存されたデータは、そのラベル込みの書式を指定しないと読み込めないと注意されています。
サンプルプログラム
生徒の名前・数学の点数・英語の点数をファイルに保存し、そのあと読み込んで表示するプログラムです。
整数を複数扱うので、fprintf と fscanf の対応関係が見えやすくなります。
ファイル名:17_4_1.c
#include <stdio.h>
int main(void)
{
/* 書き込み用ファイルを開く */
FILE *fout = fopen("score.txt", "w");
if (fout == NULL) {
printf("書き込み用ファイルを開けませんでした。\n");
return 1;
}
/* 書式付きでデータを書き込む */
char name[] = "Tanaka";
int math = 82;
int english = 76;
fprintf(fout, "%s %d %d\n", name, math, english);
/* 書き込みが終わったら閉じる */
fclose(fout);
/* 読み込み用ファイルを開く */
FILE *fin = fopen("score.txt", "r");
if (fin == NULL) {
printf("読み込み用ファイルを開けませんでした。\n");
return 1;
}
/* 読み込み先の変数を用意する */
char in_name[50];
int in_math;
int in_english;
/* 書式に従って読み込む */
if (fscanf(fin, "%49s %d %d", in_name, &in_math, &in_english) == 3) {
printf("名前:%s、数学:%d点、英語:%d点\n", in_name, in_math, in_english);
} else {
printf("データの読み込みに失敗しました。\n");
}
/* ファイルを閉じる */
fclose(fin);
return 0;
}このプログラムの動きを見てみよう
このプログラムでは、まず score.txt を w モードで開きます。
そのあと、name、math、english の3つの値を fprintf で1行にまとめて書き込みます。これは元の資料の「%s、%d、%f などの書式指定子で1行にまとめて保存する」という考え方を、整数中心のもっとシンプルな題材に置き換えたものです。
その後、いったんファイルを閉じてから、今度は r モードで開き直し、fscanf を使って同じ順番で読み込みます。
このときの書式は、
- 文字列
- 整数
- 整数
なので、出力時の %s %d %d と入力時の %49s %d %d が対応しています。
実行すると、画面には次のように表示されます。
名前:Tanaka、数学:82点、英語:76点また、score.txt の中身は次のようになります。
Tanaka 82 76fprintfによる書式付き出力をもう少し詳しく
fprintf のよいところは、数値や文字列をそのまま並べるだけでなく、整った形で出力できることです。
たとえば、
fprintf(fout, "%s %d %d\n", name, math, english);と書けば、
- %s で文字列
- %d で整数
- %d で整数
- \n で改行
という形で出力できます。
元の資料でも、出力時に改行コードを加えることで、データを1行にまとめていると説明されています。
たとえば複数人分のデータを保存したいなら、1人分ずつ1行に書くようにすると、あとで fscanf で読み込みやすくなります。
fscanfによる書式付き入力を詳しく見よう
fscanf は、決められた形式のデータを変数へ分解して読み込むのが得意です。
if (fscanf(fin, "%49s %d %d", in_name, &in_math, &in_english) == 3)この部分では、
- 文字列を in_name に入れる
- 整数を in_math に入れる
- 整数を in_english に入れる
という3項目の読み込みを行っています。
ここで大切なのが、== 3 の部分です。
これは、「3つ全部正しく読めたか」を確認しているのです。元の資料でも、返却値が期待する入力項目数なら正しく読み込めたと判断すると説明されています。
もしファイルの内容が途中で崩れていたり、整数の場所に文字が入っていたりすると、期待した個数を読み込めず、失敗したと判断できます。
%49s と書く理由
ここも初心者が押さえておきたいところです。
%49sこのように書くのは、in_name が 50 文字分の配列だからです。
文字列の最後には終端文字が必要なので、最大49文字まで読み込むようにしています。
char in_name[50];に対して %49s としておくと、配列の大きさを超えて書き込む危険を減らせます。
安全な書き方として、こうした桁数指定はとても大切です。
fscanfで気をつけたいこと
fscanf は便利ですが、書式に合っていないと正しく読み込めません。
これは元の資料でも特に注意点として取り上げられていました。
たとえば、ファイルの中身が次のようだったとします。
名前:Tanaka 数学:82 英語:76この場合、単純に
fscanf(fin, "%s %d %d", in_name, &in_math, &in_english);とは読めません。
なぜなら、ファイルの中に「名前:」「数学:」「英語:」という文字が入っていて、単純な「文字列 整数 整数」という並びではないからです。
そのため、読み込む側も、ファイルの形に合わせて、
fscanf(fin, "名前:%49s 数学:%d 英語:%d", in_name, &in_math, &in_english);のように書く必要があります。
つまり、fscanf は自由に何でも読めるわけではなく、ファイルの形式を前提に読む関数だと考えるとわかりやすいです。
どんな場面で便利なのか
fprintf と fscanf は、あらかじめ決まった並びのデータを扱うときにとても便利です。元の資料でも、CSV や固定レイアウトのような、フォーマットが決まったファイルで有効だと説明されています。
たとえば、次のような場面で使いやすいです。
| 場面 | 保存する内容の例 |
|---|---|
| テスト結果の保存 | 名前 点数 平均 |
| 商品情報の保存 | 商品名 価格 個数 |
| 都市データの保存 | 国名 首都 人口 大陸 |
| 設定ファイルの一部 | 幅 高さ 色番号 |
データの形が決まっているなら、fprintf で書いて fscanf で読み戻す、という流れはとても自然です。
実践問題
国・首都・人口・大陸の情報を含む capital.txt があります。
このファイルを読み込み、人口が 1000 以上のデータだけを population_over_1000.txt に保存するプログラムを作成してください。
capital.txt の例
Japan Tokyo 1400 Asia
UnitedStates Washington 3310 NorthAmerica
Germany Berlin 830 Europe
India NewDelhi 1380 Asia
Egypt Cairo 102 Africa実行結果例
人口が1000以上のデータを population_over_1000.txt に保存しました。出力ファイルの例
Japan Tokyo 1400 Asia
UnitedStates Washington 3310 NorthAmerica
India NewDelhi 1380 Asia解答例
#include <stdio.h>
int main(void)
{
FILE *fin = fopen("capital.txt", "r");
if (fin == NULL) {
printf("読み込み用ファイルを開けませんでした。\n");
return 1;
}
FILE *fout = fopen("population_over_1000.txt", "w");
if (fout == NULL) {
printf("書き込み用ファイルを開けませんでした。\n");
fclose(fin);
return 1;
}
char country[50];
char capital[50];
int population;
char continent[50];
while (fscanf(fin, "%49s %49s %d %49s",
country, capital, &population, continent) == 4) {
if (population >= 1000) {
fprintf(fout, "%s %s %d %s\n",
country, capital, population, continent);
}
}
fclose(fin);
fclose(fout);
printf("人口が1000以上のデータを population_over_1000.txt に保存しました。\n");
return 0;
}解答例のポイント
この問題では、1行につき
- 国名
- 首都名
- 人口
- 大陸名
の4項目を fscanf で読み込んでいます。
そのため、返却値が 4 のあいだだけループを続けます。
while (fscanf(fin, "%49s %49s %d %49s",
country, capital, &population, continent) == 4)この形にしておくと、途中で書式が崩れていたり、ファイル終端に達したりしたときに自然にループを終えられます。
これは元の資料で紹介されている「期待する入力個数を確認する」という考え方を、そのまま応用したものです。
そのあとで、population が 1000 以上なら fprintf で出力ファイルへ書き込んでいます。
if (population >= 1000) {
fprintf(fout, "%s %s %d %s\n",
country, capital, population, continent);
}このように、fscanf で読み込み、条件に合うものだけ fprintf で書くという流れは、ファイル処理の実践でとてもよく使われます。
返却値チェックを忘れないことがとても大切
今回のテーマで特に大切なのは、返却値を確認する習慣です。元の資料でも、入出力では常にエラーが起こる可能性を考え、返却値チェックを怠らないようにと明記されています。
- fopen が成功したか
- fscanf が必要な個数を読み込めたか
- 必要なら fprintf の結果も確認するか
こうした確認を入れるだけで、プログラムはずっと安全でわかりやすくなります。
fprintf と fscanf は見た目がシンプルなので、つい「書けたはず」「読めたはず」と考えてしまいがちです。けれど、実際にはファイルが存在しない、書式が違う、途中でデータが壊れている、といったことは普通に起こります。だからこそ、成功を前提にするのではなく、確認しながら進めることがとても大切です。