
C言語のきほん|ビットとデータ表現
0と1の世界をのぞけば、C言語のデータの正体が見えてくる。
これまでC言語では、int や double の値を「数値」として自然に使ってきました。
たとえば 10 を代入したり、3.14 を計算したり、比較や加算を行ったりと、表面上はとてもわかりやすく扱えます。
でも、コンピュータの内部では、それらはそのままの姿で保存されているわけではありません。
実際には、すべてのデータが 0 と 1 の並びとしてメモリに記録されています。文字も整数も小数も、内部ではすべてビットの集まりです。
この「ビットで表現されている」という事実を意識できるようになると、C言語の型の違いがぐっと理解しやすくなります。
なぜ同じ整数でも char と int があるのか、なぜ unsigned を使うと負の数が扱えないのか、なぜ型によって表せる範囲が違うのか。こうした疑問は、ビットの視点で見るととてもすっきり整理できます。
この内容は、単なる暗記ではありません。
今後、ビット演算子、メモリ操作、ファイル処理、ネットワーク、組み込み開発などを学ぶときに、必ず土台になります。
C言語をより深く理解するために、ここで一度「データの中身」に目を向けてみましょう。
C言語の整数型とは何か
C言語で扱う整数型には、符号の有無やサイズの違いによっていくつもの種類があります。
普段よく使う int も、その中のひとつにすぎません。
まずは全体像を表で整理してみましょう。
C言語の代表的な整数型
| 正式な表記 | よく使う表記 | 符号 | 一般的なサイズの例 | 表せる範囲の例 |
|---|---|---|---|---|
| char | char | 処理系依存 | 1バイト | -128〜127 または 0〜255 |
| signed char | signed char | あり | 1バイト | -128〜127 |
| unsigned char | unsigned char | なし | 1バイト | 0〜255 |
| signed short int | short | あり | 2バイト | -32768〜32767 |
| unsigned short int | unsigned short | なし | 2バイト | 0〜65535 |
| signed int | int | あり | 4バイト | -2147483648〜2147483647 |
| unsigned int | unsigned | なし | 4バイト | 0〜4294967295 |
| signed long int | long | あり | 4バイト など | 処理系依存 |
| unsigned long int | unsigned long | なし | 4バイト など | 処理系依存 |
| signed long long int | long long | あり | 8バイト | -9223372036854775808〜9223372036854775807 |
| unsigned long long int | unsigned long long | なし | 8バイト | 0〜18446744073709551615 |
| _Bool | bool | なし | 1バイト程度 | 0 または 1 |
ここで大切なのは、次の2点です。
| 注目する点 | 意味 |
|---|---|
| 符号の有無 | 負の数を扱えるかどうか |
| サイズ | 何バイト使って保存するか |
この2つによって、表せる数値の範囲が決まります。
たとえば、同じ 1バイトの型でも、signed char なら -128〜127、unsigned char なら 0〜255 を表せます。
つまり、同じ大きさの箱でも、負の数を含めるかどうかで使い方が変わるのです。
なお、char は少し特別です。
char とだけ書いた場合、その char が signed 扱いになるか unsigned 扱いになるかは処理系に依存します。
そのため、符号の有無を明確にしたい場面では signed char や unsigned char と書いたほうが安全です。
ビットとは何か
ビットは、コンピュータが扱う情報の最小単位です。
値としては 0 または 1 のどちらかしか持てません。
スイッチや電球にたとえると、とてもイメージしやすくなります。
- 0 は オフ
- 1 は オン
この 0 と 1 の並びによって、数値や文字や画像までも表現しています。
たとえば 1ビットなら、表せる状態は次の2通りです。
| ビット数 | 表せる状態 | 通り数 |
|---|---|---|
| 1ビット | 0, 1 | 2通り |
2ビットならこうなります。
| ビット数 | 表せる状態 | 通り数 |
|---|---|---|
| 2ビット | 00, 01, 10, 11 | 4通り |
3ビットなら 8通り、4ビットなら 16通りです。
このように、nビットで表せる状態の数は 2ⁿ 通りになります。
ビット数と表現できる通り数
| ビット数 | 通り数 |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
| 8 | 256 |
| 16 | 65536 |
| 32 | 4294967296 |
この考え方はとても重要です。
なぜなら、整数型の「表せる範囲」は、結局のところ何ビット使えるかで決まるからです。
バイトとは何か
ビットが最小単位なのに対して、実際のコンピュータでは 8ビットをひとまとまりにして扱うことが多く、この単位を 1バイト と呼びます。
つまり、
1バイト = 8ビット
です。
8ビットで表せる通り数は 2⁸ なので、256通りになります。
この 1バイトという単位は、C言語の型のサイズを考えるときの基本になります。
| 単位 | 中身 |
|---|---|
| 1ビット | 0 または 1 |
| 1バイト | 8ビット |
| 2バイト | 16ビット |
| 4バイト | 32ビット |
| 8バイト | 64ビット |
たとえば、int が 4バイトの処理系なら、int は 32ビットで表現されることになります。
符号なし整数の表現
まずはわかりやすい符号なし整数から見ていきましょう。
符号なし整数では、すべてのビットが数値そのものを表します。負の数は扱いません。
8ビットの unsigned char を例にすると、使えるビットは全部で8個です。
8ビットの符号なし整数のイメージ
| ビット列 | 10進数 |
|---|---|
| 00000000 | 0 |
| 00000001 | 1 |
| 00000010 | 2 |
| 00000011 | 3 |
| ... | ... |
| 11111111 | 255 |
つまり、8ビットの符号なし整数では、
0〜255
の 256通りを表せます。
これは式で書くと次のようになります。
0 〜 2⁸ - 1
一般化すると、nビットの符号なし整数で表せる範囲は次の通りです。
| nビットの符号なし整数 | 表現範囲 |
|---|---|
| 一般式 | 0 〜 2ⁿ - 1 |
たとえば 16ビットなら 0〜65535、32ビットなら 0〜4294967295 です。
符号付き整数の表現
次に、負の数も扱える符号付き整数を見ていきましょう。
符号付き整数では、一般的に最上位ビットが符号に関係する役割を持ちます。
多くの現代的な処理系では、負の数の表現に 2の補数 が使われています。
この方式では、8ビットの signed char は次の範囲を表せます。
-128〜127
同じ8ビットでも、unsigned char の 0〜255 とは範囲が違います。
8ビットの符号付き整数のイメージ
| ビット列 | 10進数 |
|---|---|
| 00000000 | 0 |
| 00000001 | 1 |
| 00000010 | 2 |
| ... | ... |
| 01111111 | 127 |
| 10000000 | -128 |
| 10000001 | -127 |
| ... | ... |
| 11111111 | -1 |
この表を見て、「なぜ 11111111 が -1 なの?」と感じるかもしれません。
これは 2の補数という決まりに従っているためです。
ここではまず、符号付き整数は正の数と負の数の両方を表すため、使える範囲が符号なし整数と異なると押さえれば大丈夫です。
一般化すると、nビットの符号付き整数の表現範囲は次のようになります。
| nビットの符号付き整数 | 表現範囲 |
|---|---|
| 一般式 | -2ⁿ⁻¹ 〜 2ⁿ⁻¹ - 1 |
たとえば 8ビットなら、
- 最小値: -2⁷ = -128
- 最大値: 2⁷ - 1 = 127
となります。
符号付きと符号なしの違いを比べる
同じビット数でも、符号の有無によって表現できる範囲は変わります。
ここは混乱しやすいので、表で並べてみましょう。
同じビット数での表現範囲の違い
| ビット数 | 符号付き | 符号なし |
|---|---|---|
| 8ビット | -128〜127 | 0〜255 |
| 16ビット | -32768〜32767 | 0〜65535 |
| 32ビット | -2147483648〜2147483647 | 0〜4294967295 |
| 64ビット | -9223372036854775808〜9223372036854775807 | 0〜18446744073709551615 |
ここからわかるのは、符号なしは負の数を捨てる代わりに、より大きな正の数まで扱えるということです。
たとえば、絶対に負にならない個数やサイズを扱うなら unsigned 系が向いている場合があります。
一方で、加減算や比較で負の値も自然に扱いたいなら signed 系のほうが扱いやすいです。
char は文字専用ではなく整数型でもある
C言語の char は、文字を扱うための型として知られていますが、実はれっきとした整数型でもあります。
1文字を数値として保存している、と考えるとイメージしやすいです。
たとえば文字 A は、文字コードでは 65 として表されます。
つまり、char に入っているのは内部的には整数です。
ファイル名:16_1_1.c
#include <stdio.h>
int main(void)
{
char ch = 'A';
printf("文字として表示: %c\n", ch);
printf("数値として表示: %d\n", ch);
return 0;
}実行結果例
文字として表示: A
数値として表示: 65このように、char は文字を保存する型であると同時に、1バイトの整数型でもあります。
だからこそ、ビットの説明で char や unsigned char がよく登場するのです。
_Bool と bool の考え方
C言語には真偽値を扱うための _Bool があります。
さらに stdbool.h をインクルードすると、bool、true、false という書きやすい形が使えます。
ファイル名:16_1_2.c
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
bool ok = true;
printf("状態: %d\n", ok);
return 0;
}実行結果例
状態: 1bool は見た目こそ特別ですが、内部的には 0 または 1 として扱われます。
これもまた、ビットによる表現の一例です。
2進数で考えると整数の仕組みがわかりやすい
私たちは普段 10進数を使っています。
たとえば 583 という数は、
- 5 × 10²
- 8 × 10¹
- 3 × 10⁰
の合計です。
2進数も同じ考え方で、基数が 10 ではなく 2 になるだけです。
たとえば 00001011 は次のように考えます。
| 桁 | 値 |
|---|---|
| 2⁷ | 0 |
| 2⁶ | 0 |
| 2⁵ | 0 |
| 2⁴ | 0 |
| 2³ | 1 |
| 2² | 0 |
| 2¹ | 1 |
| 2⁰ | 1 |
したがって、
00001011 = 8 + 2 + 1 = 11
となります。
この考え方がわかると、ビット列を見て値を読み取れるようになりますし、あとで学ぶビット演算子も理解しやすくなります。
メモリ上で整数が保存されるイメージ
変数を宣言すると、コンピュータはメモリの中にその型に応じた大きさの領域を確保します。
そして、その領域にビット列として値を保存します。
たとえば unsigned char value = 5; の場合、1バイトの領域に 5 が入ります。
2進数で 5 は 00000101 なので、内部ではそのようなビット列で保存されます。
保存イメージ
| 変数 | 型 | サイズ | 保存されるビット列の例 |
|---|---|---|---|
| value | unsigned char | 1バイト | 00000101 |
| count | int | 4バイト | 00000000 00000000 00000000 00000101 |
もちろん実際のメモリの見え方には処理系やエンディアンなどの要素もありますが、まずは「型ごとに決まったビット数の箱に値が入る」と考えると理解しやすいです。
サイズが違うと何が変わるのか
型のサイズが違うと、保存に使えるビット数が変わります。
ビット数が変わると、表せる範囲も変わります。
たとえば次のようになります。
| 型 | サイズの例 | 表現できる範囲の例 |
|---|---|---|
| signed char | 1バイト | -128〜127 |
| short | 2バイト | -32768〜32767 |
| int | 4バイト | -2147483648〜2147483647 |
| long long | 8バイト | -9223372036854775808〜9223372036854775807 |
大きい型を使えば大きな値を扱えますが、そのぶんメモリ使用量も増えます。
逆に小さい型はメモリ節約になりますが、範囲を超える値は扱えません。
そのため型選びでは、
- どのくらいの範囲の値が必要か
- メモリ効率は重要か
- 符号は必要か
を考えることが大切です。
型のサイズは処理系依存であることに注意する
C言語の型サイズは、すべてが固定ではありません。
たとえば int は多くの環境で 4バイトですが、規格上は「必ず4バイト」とは決められていません。
そのため、環境によっては long のサイズなどが異なることがあります。
実際に確認するときは sizeof 演算子を使います。
ファイル名:16_1_3.c
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
printf("char のサイズ: %zuバイト\n", sizeof(char));
printf("short のサイズ: %zuバイト\n", sizeof(short));
printf("int のサイズ: %zuバイト\n", sizeof(int));
printf("long のサイズ: %zuバイト\n", sizeof(long));
printf("long long のサイズ: %zuバイト\n", sizeof(long long));
printf("bool のサイズ: %zuバイト\n", sizeof(bool));
return 0;
}実行結果例
char のサイズ: 1バイト
short のサイズ: 2バイト
int のサイズ: 4バイト
long のサイズ: 4バイト
long long のサイズ: 8バイト
bool のサイズ: 1バイトこのように、自分の環境で確かめることはとても大切です。
特に、環境が変わると long のサイズが違うことがあるので注意しましょう。
サンプルプログラム例
整数型のサイズと値の範囲を確認するシンプルなプログラム例を作成します。
ファイル名:16_1_4.c
#include <stdio.h>
#include <limits.h>
int main(void)
{
/* 各整数型のサイズと範囲を表示する */
printf("整数型のサイズと表現範囲を確認します。\n\n");
printf("char は %zuバイトです。\n", sizeof(char));
printf("signed char の範囲: %d ~ %d\n", SCHAR_MIN, SCHAR_MAX);
printf("unsigned char の範囲: 0 ~ %u\n\n", UCHAR_MAX);
printf("short は %zuバイトです。\n", sizeof(short));
printf("short の範囲: %d ~ %d\n", SHRT_MIN, SHRT_MAX);
printf("unsigned short の範囲: 0 ~ %u\n\n", USHRT_MAX);
printf("int は %zuバイトです。\n", sizeof(int));
printf("int の範囲: %d ~ %d\n", INT_MIN, INT_MAX);
printf("unsigned int の範囲: 0 ~ %u\n\n", UINT_MAX);
printf("long long は %zuバイトです。\n", sizeof(long long));
printf("long long の範囲: %lld ~ %lld\n", LLONG_MIN, LLONG_MAX);
printf("unsigned long long の範囲: 0 ~ %llu\n", ULLONG_MAX);
return 0;
}このプログラムでわかること
このプログラムでは、次の2つを確認できます。
| 確認できること | 内容 |
|---|---|
| sizeof の結果 | 各型が何バイトで保存されるか |
| limits.h の定数 | 各型がどこまでの値を扱えるか |
limits.h は、整数型の最小値と最大値を確認するときにとても便利です。
暗記に頼るより、こうして実際に表示して確かめるほうが理解が深まります。

この図は、ビット数が増えると表現できる状態の数がどんどん増えていくことを視覚的に示すためのものです。
文章だけでも理解できますが、図で見ると「1個増えるごとに2倍になる」という感覚がつかみやすくなります。
特に、8ビットで 256通りになることを理解すると、1バイトの意味や unsigned char の 0〜255 という範囲が自然につながって見えてきます。
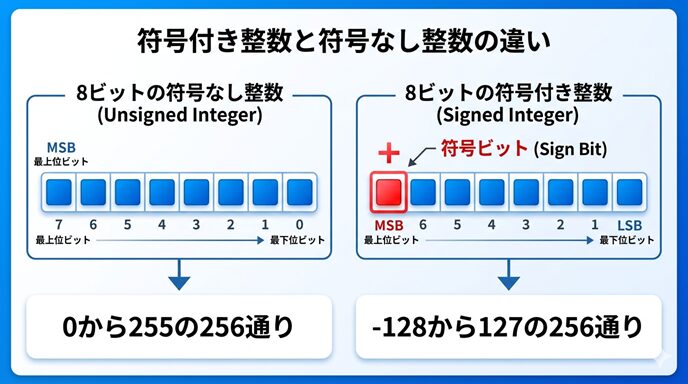
この図は、同じ8ビットでも「符号なし」と「符号付き」で意味が変わることを示すための図です。
符号なし整数では全部のビットを値の表現に使えるため、0から255まで扱えます。
一方、符号付き整数では負の数も扱う必要があるため、表現範囲が -128から127 に変わります。
この違いを図で確認しておくと、型の選び方や、なぜ unsigned をつけると最大値が大きくなるのかが理解しやすくなります。
学習するときに意識したいこと
このテーマでは、ただ範囲を丸暗記するよりも、なぜその範囲になるのかを考えることが大切です。
たとえば、
- 1バイトは 8ビット
- 8ビットなら 2⁸ = 256通り
- 符号なしなら 0〜255
- 符号付きなら -128〜127
という流れで考えられるようになると、short や int や long long にも応用できるようになります。
また、ビットを意識できるようになると、今後学ぶビット演算子の意味もぐっとわかりやすくなります。
&、|、^、~、<<、>> といった演算子は、数値をただの数としてではなく、ビット列として操作する道具だからです。
今はまだ「0と1の並びで保存されているんだな」という感覚をつかめれば十分です。
その感覚が、C言語を一段深く理解する力につながっていきます。
必要であれば次に続けて、2の補数の仕組み や ビット演算子の入門記事風解説 までそのまま同じ文体で作れます。