
C言語基礎|文字列とポインタ
文字列が分かった気になる前に、ポインタで“正体”をつかもう。
第9章で「文字列は char の配列で、最後にナル文字が付く」と学びましたよね。
そして第10章で「ポインタはアドレスを持って、* で参照外しできる」と学びました。
この2つは、別々の話に見えて、実はほぼセットです。
なぜならC言語の文字列処理は、配列・ポインタ・先頭アドレス・走査(先頭から終端まで読む)という考え方でできているからです。
ここでは、配列による文字列とポインタによる文字列を並べて、
「同じように見えるけど中身は違う」を、表と図でしっかり整理していきます。

文字列の復習:ナル文字で終わる char の並び
図:文字列 "ABC" の中身(見た目3文字、実体4要素)
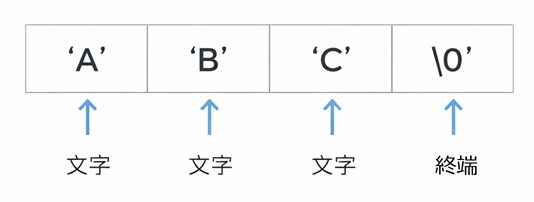
この図のポイントは、「見た目の文字数」と「必要な要素数(バイト数)」がズレることです。
最後の '\0' があるので、"ABC" は 4 要素(4バイト)になります。
配列による文字列と、ポインタによる文字列
まずは、似た見た目で動く2種類を、サクッと全体像で掴みます。
配列の文字列 vs ポインタの文字列(要点)
| 方式 | 例 | 変数の正体 | 文字列データはどこ? | sizeof の結果 |
|---|---|---|---|---|
| 配列による文字列 | char str[] = "ABC"; | char の配列 | str 自身の領域に入る | 文字数+1(例:4) |
| ポインタによる文字列 | char *ptr = "123"; | char * のポインタ | 文字列リテラル側にある | ポインタの大きさ |
この表は、「同じ printf で表示できるのに、実体が違う」という核心をまとめたものです。
サンプルプログラム
元の例は "ABC" と "123" を表示していました。
ここでは別の短い文字列にし、表示メッセージも別の日本語に置き換えます。
プロジェクト名:chap11-1-1 ソースファイル名:chap11-1-1.c
#include <stdio.h>
int main(void)
{
char msg[] = "OK"; // 配列による文字列('O','K','\0')
char *code = "NG"; // ポインタによる文字列("NG" の先頭を指す)
printf("配列の文字列: %s\n", msg);
printf("ポインタの文字列: %s\n", code);
printf("msg[0]=%c msg[1]=%c\n", msg[0], msg[1]);
printf("code[0]=%c code[1]=%c\n", code[0], code[1]);
return 0;
}このプログラムで確認できること
- msg も code も %s で表示できる(どちらも先頭文字へのポインタとして扱える)
- 添字で文字を取り出せる(ポインタも配列っぽく振る舞う)
- でも msg と code は、記憶域の持ち方が違う
配列による文字列:msg は char 配列そのもの
図:msg の構造(配列がデータを“所有”する)
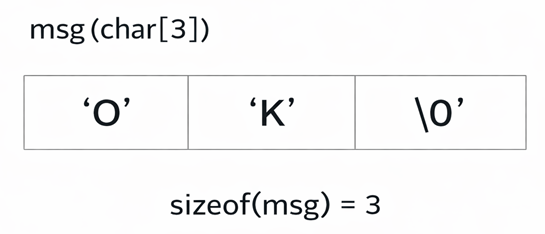
- msg は配列なので、文字列の実体(文字列データ)を自分の領域に持ちます
- msg[0] のように添字でアクセスできるのはもちろん
- sizeof(msg) は配列全体の大きさ(この例だと 3)になります
ポインタによる文字列:code は先頭文字を指すだけ
図:code の構造(ポインタ+文字列リテラル)
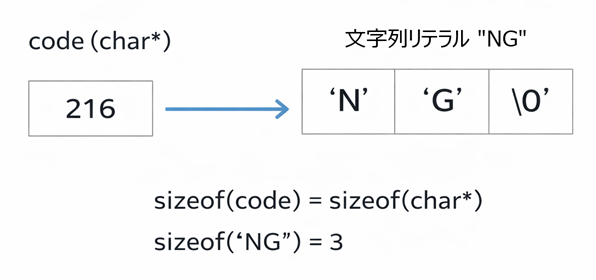
この図のポイントは2つです。
- code 自身もメモリを使う(ポインタ変数の分)
- 文字列リテラル "NG" も別にメモリを使う('N','G','\0')
だから「ポインタによる文字列は記憶域を多く使うことがある」という話につながります。
どうして両方とも %s で表示できるの?
printf の %s は、ざっくり言うとこういう依頼です。
先頭アドレスから char を順番に読んで、'\0' まで表示してください。
つまり %s が欲しいのは「文字列の先頭文字へのポインタ」です。
図:%s の動き('\0' まで走査)

- 配列 msg は、多くの文脈で先頭要素へのポインタ(&msg[0])として扱われます
- ポインタ code は、最初から先頭文字を指しています
だからどちらも %s で動きます。
添字でアクセスできる理由:ポインタと配列の表記上の可換性
ポインタ code は配列ではないのに、code[1] のように書けます。
これは、添字演算子が本質的にこうだからです。
添字の正体
| 表記 | 意味 |
|---|---|
| p[i] | *(p + i) |
なので、code[1] は *(code + 1) と同じで、
「先頭から1文字進んだ場所を参照外しして文字を得る」になります。
書き換えできる?できない?(大事な注意)
ここが「似てるけど違う」の一番の落とし穴です。
書き換えの可否(基本の考え方)
| 対象 | 例 | 文字の書き換え | 理由 |
|---|---|---|---|
| 配列の中身 | msg[0] = 'X'; | OK | msg の領域は自分の配列 |
| 文字列リテラル | code[0] = 'X'; | 原則NG | リテラルは書換不可扱いが一般的 |
実行環境によっては、文字列リテラルを書き換えようとすると実行時エラーになったり、変な挙動になったりします。
なので、ポインタで文字列を持つなら、基本は読み取り専用と思っておくのが安全です。
重要:ポインタによる文字列の宣言形式
推奨の書き方(最低限ここは覚える)
| 目的 | 例 |
|---|---|
| 読み取り専用の文字列を指したい | const char *p = "Hello"; |
| 自分で書き換える文字列が欲しい | char s[] = "Hello"; |
「書き換えたいなら配列」「読むだけならポインタ」
まずはこの使い分けが超強いです。
登場する命令(関数)の書式と役割
printf
- 書式:printf(書式文字列, 引数1, 引数2, ...);
- 何をする?:指定の形式で表示する
- %s は「char へのポインタ(文字列の先頭)」を受け取って '\0' まで表示します
使った表や図の説明(何のための表・図か)
- 「"ABC" の中身」の図は、文字列が必ず '\0' で終わることを視覚化するための図です。
- 「配列 vs ポインタ」の表は、両者の実体(所有する/指すだけ)と sizeof の違いを整理するための表です。
- 「code とリテラル」の図は、ポインタ変数と文字列リテラルが別々に記憶域を使うことを示すための図です。
- 「添字の正体」の表は、p[i] が *(p+i) に展開できるので、ポインタでも添字アクセスできる理由を説明するための表です。