
C言語のきほん|ファイル処理の注意点(改行コードとエンディアン)
見えない違いが、動作の差になる。改行コードとエンディアンを知ると、ファイル処理はもっと確実になる。
ファイル入出力を学んでくると、文字列を保存したり、構造体をバイナリファイルに書き込んだりできるようになります。
ここまでくると、「ファイルに保存できた」「読み込めた」というだけでもかなり前進です。
ただ、実際の開発では、自分の環境では正しく動くのに、別の環境ではうまくいかないということが起こることがあります。
その原因のひとつが、改行コードです。
テキストファイルでは、改行を表す方法がOSによって異なるため、Windowsで作ったファイルをLinuxで開いたときや、その逆の場合に、表示や処理の結果が変わることがあります。
もうひとつの大事な注意点が、エンディアンです。
これはバイナリファイルを扱うときに関係する考え方で、数値をメモリやファイルに保存するときのバイトの並び順を表します。
同じ数値でも、環境によって並び順が変わることがあるため、異なるシステム間でバイナリデータをやり取りするときには注意が必要です。
つまり、ファイル処理では、
- テキストファイルでは改行コード
- バイナリファイルではエンディアン
が重要な注意点になります。
どちらも普段は見えにくい存在ですが、知っているかどうかでトラブルへの強さがかなり変わります。
ここでは、改行コードとエンディアンについて、できるだけやさしく、でも実践で困らないように、順番に丁寧に見ていきましょう。
なぜファイル処理で注意点が出てくるのか
ファイルは、ただデータを保存する箱ではありません。
実際には、OSやCPUの仕組みの影響を受けることがあります。
たとえば、同じ文章を保存したつもりでも、改行の表し方が違えば、別のOSで開いたときに見え方が変わることがあります。
また、同じ整数を保存したつもりでも、バイトの並び順が違えば、別の環境では別の値として読まれてしまうことがあります。
このように、ファイル処理ではデータそのものだけでなく、どのような形式で保存されているかも大切です。
| 種類 | 主な注意点 | 影響するもの |
|---|---|---|
| テキストファイル | 改行コード | OS |
| バイナリファイル | エンディアン | CPUやシステム構成 |
この表を見てもわかるように、テキストとバイナリでは、注意する場所が少し違います。
テキストファイルで重要な改行コード
テキストファイルでは、改行をどう表すかがOSによって異なります。
普段は Enter キーを押すだけなので意識しにくいですが、内部では改行を表す特別な文字が使われています。
主なOSごとの改行コードは次のとおりです。
| OS | 改行コード | ASCII表記 | 説明 |
|---|---|---|---|
| Windows | \r\n | CR+LF | 行頭に戻ってから次の行へ進む |
| Unix系(Linux、macOSなど) | \n | LF | 次の行へ進む |
| 古いMac(Mac OS 9まで) | \r | CR | 行頭に戻る |
ここで出てくる CR と LF は、もともとはタイプライターの動作に由来する考え方です。
- CR
キャリッジリターン。行の先頭に戻る動きです。 - LF
ラインフィード。次の行へ進む動きです。
Windows はこの2つを組み合わせて改行を表し、Linux や macOS では LF だけで改行を表すのが一般的です。
改行コードの違いを図でイメージしよう
改行コードは文字だけで説明されると少しわかりにくいので、図でイメージすると理解しやすくなります。
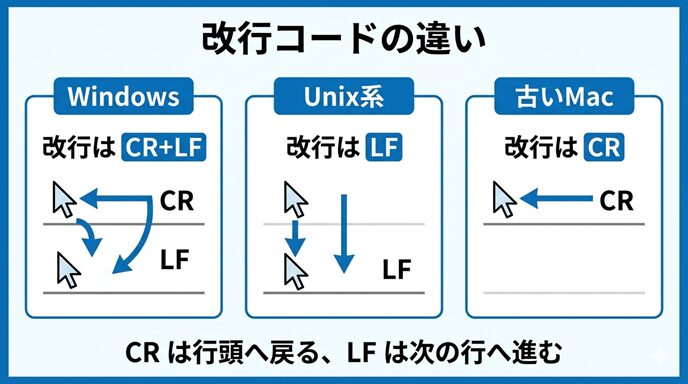
この図では、OSごとに改行の表現が違うことを並べて示しています。
Windows は CR+LF の2文字、Unix系は LF の1文字、古いMacは CR の1文字を使います。
大事なのは、見た目には同じ「改行」でも、内部のデータとしては違う場合があることです。
そのため、別のOSで扱ったときに、行末に余計な文字が残ったり、改行として認識されなかったりすることがあります。
テキストモードでは改行コードが自動変換される
C言語でファイルをテキストモードで開くと、OSによって改行コードの扱いが変わることがあります。
たとえば、次のようにファイルを開いたとします。
FILE *fp = fopen("test.txt", "w");これはテキスト書き込みモードです。
この状態で \n を書き込むと、OSによって次のような動きになります。
| 環境 | \n の扱い |
|---|---|
| Windows | 自動的に \r\n に変換されることがある |
| Linux、macOS | \n のまま書き込まれることが多い |
つまり、プログラム上では同じ \n を書いていても、実際にファイルへ保存される内容は環境によって異なる場合があります。
これはテキストファイルを自然に扱うためには便利ですが、内部データを厳密に一致させたい場合には注意が必要です。
バイナリモードでは自動変換されない
ファイルをバイナリモードで開くと、改行の自動変換は行われません。
たとえば、
FILE *fp = fopen("test.txt", "wb");のように開いた場合、\n はそのままのバイト列として保存されます。
この違いはとても大切です。
テキストモードでは「人が扱いやすいように」変換が入ることがありますが、バイナリモードでは「そのまま保存する」ことが優先されます。
そのため、バイナリデータを扱うときにテキストモードを使うのは危険です。
特に Windows では、改行変換によってデータが壊れたように見えることもあるため、バイナリファイルは必ず rb や wb で開く必要があります。
異なるOS間で起きやすい改行コードの問題
改行コードの違いは、異なるOS間でファイルをやり取りしたときに問題になりやすいです。
代表的な例を整理すると、次のようになります。
| 状況 | 起こりやすい問題 |
|---|---|
| Windowsで作成したファイルをLinuxで開く | 行末に \r が残ることがある |
| Linuxで作成したファイルを古いWindows環境で開く | 改行がうまく反映されないことがある |
| 改行コードを前提に文字列処理している | 余分な文字が混じって判定に失敗することがある |
たとえば、Windows のファイルを Linux で処理したとき、行末に \r が残ってしまい、文字列比較で予想外に一致しないことがあります。
見た目では同じに見えても、内部ではこうなっていることがあります。
"apple\r\n"Linux 側で 1行を読んで処理したときに、末尾の \r が残れば、
"apple\r"のような状態になることがあります。
これでは、単純に apple と比較しても一致しません。
改行コードの問題に気づきやすい例
たとえば、1行読み込んだあとで末尾の改行を取り除くつもりでも、環境によっては \n だけでなく \r も考慮しないといけないことがあります。
このように、改行コードの違いは、表示だけでなく、文字列処理の結果そのものに影響することがあります。
高機能なエディタ、たとえば VS Code などでは、改行コードの種類を確認したり変換したりできます。
そのため、異なるOSのファイルを扱うときは、エディタ側の設定も役立ちます。
サンプルプログラム
文字列を書き込んだあと、そのファイルをバイナリモードで読み込んで1バイトずつ16進数表示するプログラムです。
これなら、改行コードがどのように保存されているかを目で確認しやすくなります。
ファイル名:17_6_1.c
#include <stdio.h>
int main(void)
{
/* テキストモードでファイルを書き込む */
FILE *fout = fopen("newline_sample.txt", "w");
if (fout == NULL) {
printf("書き込み用ファイルを開けませんでした。\n");
return 1;
}
/* 2行の文字列を書き込む */
fputs("こんにちは\n", fout);
fputs("C言語の改行確認です\n", fout);
fclose(fout);
/* バイナリモードで読み込んで中身を確認する */
FILE *fin = fopen("newline_sample.txt", "rb");
if (fin == NULL) {
printf("読み込み用ファイルを開けませんでした。\n");
return 1;
}
int ch;
printf("ファイルの内容を16進数で表示します\n");
while ((ch = fgetc(fin)) != EOF) {
printf("%02X ", (unsigned char)ch);
}
printf("\n");
fclose(fin);
return 0;
}このプログラムでわかること
このプログラムでは、まずテキストモードでファイルを書き込みます。
ここで \n を使っていますが、Windows では内部的に \r\n に変換されることがあります。
そのあと、同じファイルを rb で開いて、1バイトずつ16進数で表示します。
こうすると、実際にどのような改行コードが保存されたのかを確認しやすくなります。
たとえば Windows では、改行部分に 0D 0A が見えることがあります。
Unix系では 0A だけが見えることが多いです。
つまり、このプログラムは「見た目には同じ改行」が、実際には違うデータとして保存されることを確認する例になっています。
次に知っておきたいエンディアン
ここからはバイナリファイル側の注意点として、エンディアンを見ていきます。
改行コードはテキストファイルの問題でしたが、エンディアンはバイナリファイルを扱うときに重要です。
特に整数をそのまま保存したり、構造体をそのまま書き込んだりするときに関係します。
エンディアンとは、簡単に言うと数値を複数バイトで保存するときの並び順です。
たとえば、4バイトの整数 0x12345678 を保存するとき、バイトの並べ方には2つの方式があります。
バイトオーダーとは何か
バイトオーダーとは、複数バイトでできた数値を、メモリやファイルにどの順番で並べるか、という考え方です。
この並び順の方式をエンディアンと呼びます。
エンディアンには、主に次の2種類があります。
| 方式 | 並び方 |
|---|---|
| リトルエンディアン | 下位バイトから先に並ぶ |
| ビッグエンディアン | 上位バイトから先に並ぶ |
リトルエンディアンとは
リトルエンディアンでは、最下位バイトが先頭に置かれます。
たとえば、0x12345678 を保存すると、
78 56 34 12の順になります。
多くのPC、特に Intel 系の環境では、この方式が使われています。
ビッグエンディアンとは
ビッグエンディアンでは、最上位バイトが先頭に置かれます。
同じ 0x12345678 を保存すると、
12 34 56 78の順になります。
こちらは、数字をそのまま左から書いた感覚に近いので、直感的に感じやすいことがあります。
1001 が逆順に見える理由
10進数の 1001 をダンプすると、
E9 03 00 00のように見えます。
10進数の 1001 は16進数では 0x03E9 ですから、ぱっと見ると 00 00 03 E9 のように並びそうに思えます。
けれど、リトルエンディアンの環境では、下位バイトが先に来るので、
E9 03 00 00となります。
ここがエンディアンのいちばんわかりやすい例です。
つまり、数値の意味は同じでも、保存されたバイト列の見え方が違うのです。
エンディアンを図でイメージしよう

この図では、同じ 0x12345678 という値でも、保存のしかたによってバイトの並びが変わることを示しています。
左側のリトルエンディアンでは、いちばん小さい位のバイトから並びます。
右側のビッグエンディアンでは、いちばん大きい位のバイトから並びます。
この違いは、ふだん数値として扱っているだけでは見えません。
けれど、バイナリファイルを直接読んだり、別の環境へ渡したりすると、はっきり表面化します。
エンディアンの違いが問題になる場面
同じ環境の中だけで完結するなら、エンディアンをそれほど強く意識しなくても動くことが多いです。
けれど、次のような場面では注意が必要です。
| 場面 | 問題 |
|---|---|
| 異なるCPU間でバイナリファイルをやり取りする | 数値の読み取り結果が変わることがある |
| 通信データを数値として送受信する | 相手側と並び順をそろえる必要がある |
| 構造体をそのまま保存して別環境で読む | 値が化ける可能性がある |
つまり、バイナリデータを別の環境へ持っていくときに特に気をつける必要があります。
サンプルプログラム
ここでは、整数をバイナリファイルへ書き込み、その内容を1バイトずつ16進数で表示するプログラムを作成します。
エンディアンの違いが実際にどう現れるかを見やすくなります。
ファイル名:17_6_2.c
#include <stdio.h>
int main(void)
{
/* 保存する整数 */
int value = 1001;
/* バイナリファイルへ書き込む */
FILE *fout = fopen("number.dat", "wb");
if (fout == NULL) {
printf("書き込み用ファイルを開けませんでした。\n");
return 1;
}
if (fwrite(&value, sizeof(value), 1, fout) != 1) {
printf("数値の書き込みに失敗しました。\n");
fclose(fout);
return 1;
}
fclose(fout);
/* バイナリファイルを1バイトずつ読み込んで表示する */
FILE *fin = fopen("number.dat", "rb");
if (fin == NULL) {
printf("読み込み用ファイルを開けませんでした。\n");
return 1;
}
int ch;
printf("number.dat の内容を16進数で表示します\n");
while ((ch = fgetc(fin)) != EOF) {
printf("%02X ", (unsigned char)ch);
}
printf("\n");
fclose(fin);
return 0;
}このプログラムでわかること
このプログラムでは、整数 1001 をそのままバイナリファイルに書き込んでいます。
そのあと、そのファイルを1バイトずつ読み込んで16進数で表示しています。
もしリトルエンディアンの環境なら、1001 は 0x03E9 なので、
E9 03 00 00のような並びが見えることがあります。
一方で、ビッグエンディアンの環境なら、
00 00 03 E9のようになる可能性があります。
この違いこそが、エンディアンです。
テキストファイルとバイナリファイルで注意点が違う
ここまでの内容を整理すると、テキストファイルとバイナリファイルでは、注意するポイントがかなり違います。
| ファイル形式 | 注意点 | 内容 |
|---|---|---|
| テキストファイル | 改行コード | OSごとに表現が違う |
| バイナリファイル | エンディアン | 数値のバイト順が違う |
この違いを知っておくと、
テキストファイルで行末の余分な文字に悩んだときにも、
バイナリファイルで数値が変に見えたときにも、
原因を見つけやすくなります。
実際の開発で意識したいこと
最後に、実際の開発で意識しておきたい考え方を整理しておきます。
テキストファイルでは
- 改行コードの違いを意識する
- 別OSのファイルを読むときは行末の \r に注意する
- 高機能エディタで改行コードを確認する
バイナリファイルでは
- rb や wb で開く
- 異なる環境間で共有するならエンディアンを意識する
- 構造体のそのまま保存は環境依存の可能性があると知っておく
こうした視点を持っておくと、ファイル処理のトラブルにかなり強くなります。
見えない差を知ることが、安定したファイル処理につながる
改行コードもエンディアンも、普段はあまり目に見えません。
けれど、うまく動かないときの原因としてはとても重要です。
テキストファイルでは「同じ改行に見えるのに違う」ということがあり、
バイナリファイルでは「同じ数値なのに並びが違う」ということがあります。
どちらも、ファイルをただの保存先ではなく、環境の影響を受けるデータ形式として見ると理解しやすくなります。
C言語でファイル処理をしっかり扱うなら、データそのものだけでなく、
そのデータがどのようなルールで保存されているかにも目を向けることがとても大切です。
この視点が持てるようになると、ファイル処理がぐっと確実で実践的なものになっていきます。