
C言語のきほん|入れ子構造体とポインタ
入れ子構造体をポインタでたどれるようになると、複雑なデータも順序立てて読み書きできるようになる。
構造体を学んでいくと、ひとつのまとまりの中に、さらに別のまとまりを入れたくなる場面が出てきます。
たとえば、人の情報の中に生年月日を入れたり、学生情報の中に身体データや成績データを入れたりするような場面です。こうした形を入れ子構造体と呼びます。
さらにC言語では、その入れ子構造体もポインタを使って操作できます。
つまり、外側の構造体を指すポインタを用意して、そのポインタを通して内側の構造体のメンバまでたどっていけるわけです。
ここで最初に混乱しやすいのが、どこで -> を使い、どこで . を使うのかという点です。
外側の構造体をポインタで指しているなら、まずは -> で外側のメンバにアクセスします。
でも、その先にある内側の構造体は「ポインタ」ではなく「構造体そのもの」であることが多いので、その中のメンバには . でアクセスします。
この違いが分かるようになると、
- 構造体の中に構造体があるときの読み方
- ポインタを通してどこまでアクセスできるのか
- 配列と組み合わせたときにどう処理するのか
- 少し大きめのデータ構造をどう整理して扱うのか
といった点が一気に見えやすくなります。
ここでは、まず入れ子構造体にポインタでアクセスする基本を確認して、そのあとに配列や実践問題へ広げながら、やさしく順番に整理していきましょう。
入れ子構造体をポインタで指すとは何か
まず、入れ子構造体とは何かを簡単に確認しておきます。
たとえば、Date という日付の構造体と、Person という個人情報の構造体があるとします。
typedef struct {
int year;
int month;
int day;
} Date;
typedef struct {
char name[50];
Date birth;
} Person;この Person の中には、birth というメンバがあります。
そして birth の型は Date です。
つまり、Person の中に Date が入っているので、これが入れ子構造体です。
ここで Person 型の変数 person があれば、
Person *p = &person;のように、そのアドレスをポインタ p に入れられます。
この p を通して、name や birth.year などにアクセスするのが、入れ子構造体をポインタで指すということです。
まず外側をたどってから、内側へ進む
入れ子構造体をポインタで扱うときは、アクセスの流れを段階的に考えると分かりやすいです。
たとえば、
p->birth.yearという書き方があったとします。
これは次の流れです。
- p が指す Person 構造体にアクセスする
- その中の birth メンバを取り出す
- birth の中の year メンバを参照する
つまり、いきなり全部をひとかたまりで見るのではなく、外側から順にたどるのがポイントです。
なぜ p->birth->year ではないのか
ここは特によくある疑問です。
見た目だけだと、
p->birth->yearと書けそうに見えますよね。
でも、これは通常は正しくありません。
理由は、birth がポインタではなく構造体そのものだからです。
-> 演算子は、ポインタが指している先の構造体メンバにアクセスするときに使います。
一方、birth は Date 型の構造体そのものなので、その中の year へは . でアクセスします。
つまり、
- p は Person へのポインタ → p->birth
- birth は Date 型の構造体 → p->birth.year
という流れになります。
使い分けを表で整理する
| 対象 | 書き方 |
|---|---|
| ポインタが指す外側構造体のメンバ | p->member |
| 取り出した内側構造体のメンバ | outer.inner |
| 入れ子構造体をポインタ経由でたどる | p->inner.member |
この表の感覚がつかめると、入れ子構造体とポインタの組み合わせがかなり読みやすくなります。
サンプルプログラムで確認する
書籍情報と発売日の例で説明します。
ファイル名:15_10_1.c
#include <stdio.h>
// 発売日を表す構造体
typedef struct {
int year;
int month;
int day;
} ReleaseDate;
// 書籍情報を表す構造体
typedef struct {
char title[50];
ReleaseDate publish;
} Book;
int main(void)
{
Book book = {"C言語しっかり入門", {2024, 4, 12}};
Book *p = &book;
printf("書名: %s\n", p->title);
printf("発売日: %d/%d/%d\n",
p->publish.year, p->publish.month, p->publish.day);
return 0;
}実行結果例
書名: C言語しっかり入門
発売日: 2024/4/12サンプルプログラムを順に読み解く
まず、ReleaseDate 型を定義しています。
typedef struct {
int year;
int month;
int day;
} ReleaseDate;これは、年・月・日をまとめた日付の構造体です。
次に、Book 型を定義しています。
typedef struct {
char title[50];
ReleaseDate publish;
} Book;ここでは、publish が ReleaseDate 型です。
つまり、Book の中に ReleaseDate が入っています。
そのあと、Book 型の変数 book を初期化しています。
Book book = {"C言語しっかり入門", {2024, 4, 12}};このとき、
- title に C言語しっかり入門
- publish.year に 2024
- publish.month に 4
- publish.day に 12
が入ります。
さらに、
Book *p = &book;で、book を指すポインタ p を作っています。
ここから先は、
p->titleで外側の Book の title にアクセスし、
p->publish.yearで Book の中の publish、その中の year を参照しています。
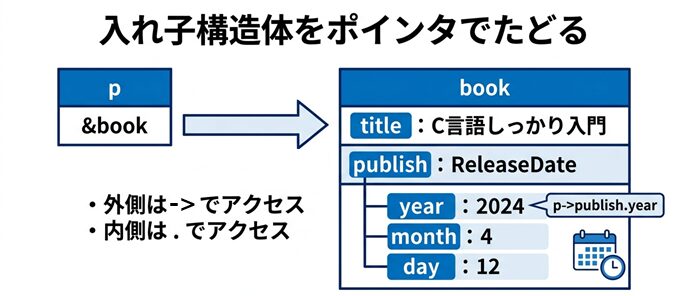
この図では、ポインタ p が book を指していること、そして book の中に publish という入れ子の構造体があることを表しています。
最初に p->publish で外側の構造体のメンバへ進み、そのあと .year で内側の構造体メンバへアクセスします。
この順番を理解すると、入れ子構造体のポインタ操作がかなり読みやすくなります。
外側も内側もポインタだったらどうなるか
今回の基本例では、外側だけがポインタで、内側は普通の構造体でした。
そのため、
p->publish.yearのように書きました。
もし内側のメンバ publish 自体がポインタだったら、その先には -> を使います。
でも今学んでいる基本では、内側は構造体そのものなので、.member を使うと整理しておくのが分かりやすいです。
入れ子構造体と配列を組み合わせるとどうなるか
入れ子構造体は、配列と組み合わせてもよく使います。
たとえば、複数人分の学生情報を配列にして、その中に身体データや成績データを入れておく形です。
このとき、配列の先頭を指すポインタを使えば、各要素を順番に処理できます。
つまり、
- 配列
- ポインタ
- 入れ子構造体
の3つが組み合わさるわけです。
見た目は少し長くなりますが、意味を分解して考えれば大丈夫です。
実践問題
次の要件を満たすプログラムを作成してください。
① x座標とy座標を持つ点 Point の構造体を定義する。
② 要素数20の配列を Point 型の構造体で作成する。
③ 各点の x座標 と y座標 を 0~99 の範囲の乱数で設定する。
④ ポインタを使って配列の各要素を指し、表示する。
解答例
ファイル名:15_10_2.c
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef struct {
int x;
int y;
} Point;
int main(void)
{
Point points[20];
Point *p = points;
srand((unsigned)time(NULL));
for (int i = 0; i < 20; i++) {
(p + i)->x = rand() % 100;
(p + i)->y = rand() % 100;
}
printf("生成された点の座標\n\n");
for (int i = 0; i < 20; i++) {
printf("(%d, %d)", (p + i)->x, (p + i)->y);
if (i != 19) {
printf(", ");
}
if ((i + 1) % 6 == 0) {
printf("\n");
}
}
printf("\n");
return 0;
}実行結果例
生成された点の座標
(65, 77), (73, 21), (34, 77), (88, 95), (26, 73), (20, 45)
(90, 79), (15, 53), (4, 85), (71, 61), (69, 6), (44, 58)
(54, 10), (5, 60), (33, 52), (18, 31), (5, 39), (53, 76)
(37, 34), (93, 32)解説
この問題では、Point 型の構造体配列を用意し、その先頭をポインタ p で指しています。
そのうえで (p + i)->x や (p + i)->y のように書いて、各要素のメンバへアクセスしています。
構造体配列をポインタで順番に処理する基本を確認するのにちょうどよい問題です。
実践問題
ここでは、氏名データを元の例とは別の名前に変更してあります。
次の要件を満たすプログラムを作成してください。
① 学生の身体情報と成績情報を入れ子構造体で定義する。
② 学生情報の配列を用意し、配列の最後には id = 0 の終端データを入れる。
③ BMI を計算し、各学生の名前、身長、体重、BMI を表示する。
④ 配列はポインタを使って操作する。
⑤ BMI は次の式で求める。身長は cm から m に変換すること。
BMI = 体重(kg) / (身長(m) × 身長(m))
解答例
ファイル名:15_10_3.c
#include <stdio.h>
typedef struct {
double height;
double weight;
} BodyInfo;
typedef struct {
int math;
int english;
int info;
} ScoreInfo;
typedef struct {
int id;
char name[20];
BodyInfo body;
ScoreInfo score;
} Student;
int main(void)
{
Student students[] = {
{1, "石田 恒一", {168.3, 70.3}, {78, 65, 71}},
{2, "上村 拓海", {175.5, 65.3}, {88, 87, 92}},
{3, "大西 翔太", {165.2, 56.4}, {67, 94, 70}},
{4, "川本 恒一", {160.5, 58.0}, {85, 81, 78}},
{5, "坂井 颯太", {174.3, 89.4}, {65, 94, 83}},
{6, "中原 恒一", {186.3, 78.3}, {76, 82, 88}},
{0, "", {0.0, 0.0}, {0, 0, 0}}
};
Student *p = students;
printf("【学生のBMI一覧】\n\n");
printf("ID | 名前 | 身長(cm) | 体重(kg) | BMI\n");
while (p->id != 0) {
double height_m = p->body.height / 100.0;
double bmi = p->body.weight / (height_m * height_m);
printf("%d | %-10s | %7.1f | %7.1f | %.2f\n",
p->id, p->name, p->body.height, p->body.weight, bmi);
p++;
}
return 0;
}実行結果例
【学生のBMI一覧】
ID | 名前 | 身長(cm) | 体重(kg) | BMI
1 | 石田 恒一 | 168.3 | 70.3 | 24.82
2 | 上村 拓海 | 175.5 | 65.3 | 21.20
3 | 大西 翔太 | 165.2 | 56.4 | 20.67
4 | 川本 恒一 | 160.5 | 58.0 | 22.52
5 | 坂井 颯太 | 174.3 | 89.4 | 29.43
6 | 中原 恒一 | 186.3 | 78.3 | 22.56解説
この問題では、Student の中に BodyInfo と ScoreInfo を含めています。
そのため、身長は p->body.height、体重は p->body.weight のようにアクセスします。
また、配列の最後に id = 0 のデータを置いているので、while (p->id != 0) で終端まで処理できます。
入れ子構造体とポインタ、さらに終端付き配列の考え方をまとめて練習できる問題です。
入れ子構造体をポインタでたどるときの読み方
たとえば、
p->body.heightという式があったら、次のように読むと分かりやすいです。
- p が指している Student を見る
- その中の body を見る
- body の中の height を見る
この順序を毎回意識すると、長い式でも落ち着いて読めます。
実践問題
次の要件を満たすプログラムを作成してください。
① 学生の情報を管理する構造体を定義する。ただし、点数は要素数3の配列で定義する。
② 学生データを6件分、構造体配列で初期化する。
③ 構造体の配列をポインタで指す。
④ ポインタを使って全体の最高得点と、その科目名を求めて表示する。
⑤ ポインタを使って全体の最低得点と、その科目名を求めて表示する。
⑥ 同じ点数が複数科目にある場合には、科目名を並べて表示する。
解答例
ファイル名:15_10_4.c
#include <stdio.h>
#define SUB_COUNT 3
typedef struct {
int id;
char name[20];
int scores[SUB_COUNT];
} Student;
int main(void)
{
Student students[6] = {
{1, "木下 悠真", {78, 65, 71}},
{2, "藤田 拓真", {88, 87, 92}},
{3, "西村 颯人", {67, 94, 70}},
{4, "安藤 悠真", {85, 81, 78}},
{5, "森本 颯真", {65, 94, 83}},
{6, "松田 恒一", {76, 82, 88}}
};
Student *p = students;
char *subjects[SUB_COUNT] = {"数学", "英語", "情報"};
int max_score = p->scores[0];
int min_score = p->scores[0];
for (int i = 0; i < 6; i++) {
for (int j = 0; j < SUB_COUNT; j++) {
if ((p + i)->scores[j] > max_score) {
max_score = (p + i)->scores[j];
}
if ((p + i)->scores[j] < min_score) {
min_score = (p + i)->scores[j];
}
}
}
printf("最高得点の科目:");
for (int j = 0; j < SUB_COUNT; j++) {
int printed = 0;
for (int i = 0; i < 6; i++) {
if ((p + i)->scores[j] == max_score) {
printf("%s ", subjects[j]);
printed = 1;
break;
}
}
if (printed) {
/* 何もしない */
}
}
printf("%d点\n", max_score);
printf("最低得点の科目:");
for (int j = 0; j < SUB_COUNT; j++) {
int printed = 0;
for (int i = 0; i < 6; i++) {
if ((p + i)->scores[j] == min_score) {
printf("%s ", subjects[j]);
printed = 1;
break;
}
}
if (printed) {
/* 何もしない */
}
}
printf("%d点\n", min_score);
return 0;
}実行結果例
最高得点の科目:数学 英語 94点
最低得点の科目:英語 65点解説
この問題では、Student の中に scores[3] という配列メンバがあります。
そのため、(p + i)->scores[j] のように、構造体配列 + ポインタ + 配列メンバという少し長い形でアクセスしています。
見た目は長いですが、意味を分解すると、
- (p + i) で i 番目の学生
- ->scores でその学生の点数配列
- [j] で j 番目の科目
という流れです。
ここまで読めるようになると、かなり実践的なデータ構造も落ち着いて扱えるようになります。
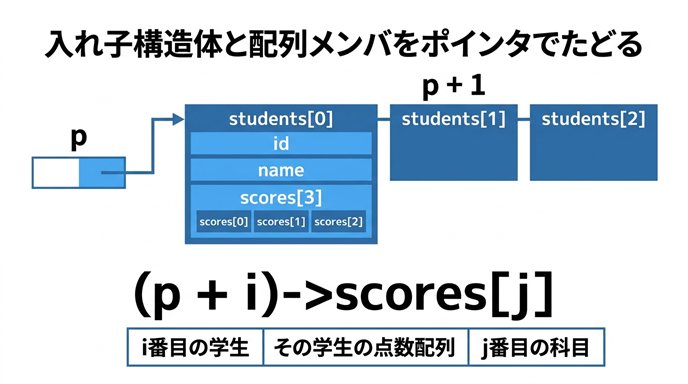
この図では、構造体配列の先頭を指すポインタから、各学生データ、その中の配列メンバまでを順にたどる流れを表しています。
(p + i)->scores[j] という式は長く見えますが、実際には「i番目の学生の j番目の点数」を見ているだけです。
階層を分けて考えることで、長いアクセス式も落ち着いて読めるようになります。
よくある間違い
p->birth->year と書いてしまう
これは、birth がポインタであるかのように読んでしまっています。
birth が構造体そのものなら、正しくは
p->birth.yearです。
-> と . の切り替えを意識しない
外側がポインタなら -> を使います。
その先にあるのが構造体そのものなら . を使います。
ここを段階ごとに意識することが大切です。
長い式をひと目で読もうとして混乱する
たとえば
(p + i)->scores[j]のような式は、一気に見ようとすると分かりにくいです。
でも、
- p + i
- ->scores
- [j]
と分けて考えれば整理できます。
この記事で押さえておきたいポイント
| ポイント | 内容 |
|---|---|
| 外側の構造体がポインタ | p->member |
| 内側の構造体が普通の構造体 | .member |
| 基本の形 | p->inner.member |
| 配列と組み合わせた形 | (p + i)->inner.member |
| 配列メンバまで含む形 | (p + i)->scores[j] |
| 読み方のコツ | 外側から順番にたどる |
入れ子構造体とポインタを理解すると、構造が少し複雑なデータでも、意味のまとまりを崩さずに扱えるようになります。
最初は式が長く見えても、外側から順にたどる意識を持てば、構造体・ポインタ・配列が自然につながって見えてきます。