
C言語入門|文字コードとファイル形式の基本
文字が表示される仕組みの正体
ここまで学んできた内容を振り返ると、
コンピュータが扱えるのは 0と1だけ でしたね。
では、私たちが普段書いているソースコードや文章ファイルに含まれる
アルファベットや記号は、いったいどうやって表現されているのでしょうか。
実はそこには、
「0と1の並び」と「文字」との対応表 が用意されているのです。
この対応ルールを理解すれば、
文字が表示される仕組みと、
テキストファイルとバイナリファイルの違いが一気につながってきます。
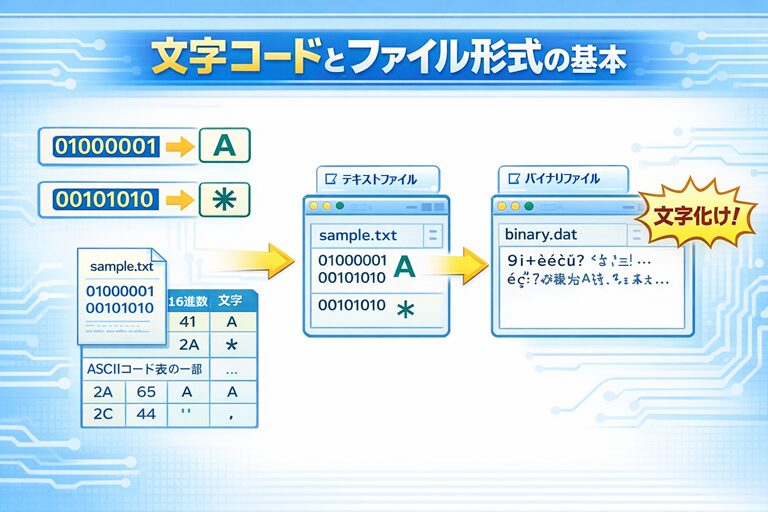
文字コードとは何か
コンピュータは文字を直接扱えません。
そこで、次のような約束を作りました。
| 数値(0と1の並び) | 表す文字 |
|---|---|
| 01000001 | A |
| 00101010 | * |
このように、
- どの数値が
- どの文字を表すのか
を決めたルールを 文字コード といいます。
代表的な文字コードが ASCIIコード です。
ASCIIコードでは、
| 10進数 | 2進数 | 文字 |
|---|---|---|
| 65 | 01000001 | A |
| 42 | 00101010 | * |
のように対応が決められています。
ソースコードが読める理由
「でも、今まで書いたC言語のソースコードって、
0と1じゃなくて普通に文字で見えますよね?」
その理由はとてもシンプルです。
テキストエディタが文字コードを使って変換しているから です。
コンピュータの中では、テキストファイルも実際には
次のような2進数のデータとして保存されています。
01110011 01110101 01101011 01101001 01110010 01101001
テキストエディタは、
- ファイルを読み込む
- 文字コード(ASCIIなど)に従って
- 2進数を文字に変換
- 画面に表示
という処理をしてくれています。
だから私たちは、
ファイルの中身を「文字」として読めるのです。
テキストファイルとは何か
ここで テキストファイル を定義してみましょう。
テキストファイルとは、
ファイルの中身すべてが、文字コードとして解釈できるファイル
のことです。
代表的なテキストファイルには、次のようなものがあります。
| 例 | 内容 |
|---|---|
| .txt | 文章 |
| .c | C言語のソースコード |
| .csv | カンマ区切りのデータ |
CSVファイルを例にすると、
- Excelで開いても
- メモ帳で開いても
中身は同じ文字データです。
開くアプリケーションが違うだけで、
保存されている内容は「文字の集まり」なのです。
日本語と文字コードの話
ASCIIコードで表現できる文字は256種類です。
これはアルファベット中心の世界では十分でした。
しかし、日本語はどうでしょう。
| 種類 | 数 |
|---|---|
| ひらがな | 約50 |
| カタカナ | 約50 |
| 漢字 | 数千〜数万 |
とても256種類では足りません。
そのため、日本語を扱うために、
- Shift_JIS
- EUC-JP
- UTF-8
といった、より多くの文字を扱える文字コードが登場しました。
C言語で全角文字を扱う際の詳細は、
付録の解説を参照すると理解が深まります。
バイナリファイルとは何か
「バイナリファイルって、2進数って意味ですよね?
テキストファイルと何が違うんですか?」
ここで大事なポイントがあります。
テキストファイルもバイナリファイルも、
どちらも中身は2進数 です。
違いはここです。
| 種類 | 特徴 |
|---|---|
| テキストファイル | すべて文字コードとして解釈できる。 |
| バイナリファイル | 文字コードとして解釈できない部分がある。 |
バイナリファイルは、
- プログラムの命令
- 数値データ
- 制御情報
などが混ざって保存されています。
そのため、テキストエディタで開くと、
意味不明な記号の塊に見えてしまいます。
バイナリファイルにも文字が見える理由
バイナリファイルをメモ帳で開くと、
ところどころ文字が読めることがあります。
これは、
- エラーメッセージ
- ファイル名
- 表示用の文字列
など、文字データも一部に含まれている ためです。
ただし、ファイル全体を文字コードで正しく解釈することはできません。
標準化されたバイナリファイル
基本的にバイナリファイルは、
- OS
- CPU
- ソフトウェア
に依存しやすい形式です。
しかし例外もあります。
| 形式 | 特徴 |
|---|---|
| JPEG | 画像の国際標準 |
| PNG | 画像の国際標準 |
これらは国際的に仕様が決められているため、
異なるOSや環境でも共通して扱えます。
「バイナリだけど、どこでも開ける」
という便利な存在です。
まとめ:文字コードとファイル形式の関係
ここまでを整理すると、次のようになります。
- コンピュータの中では、すべてが0と1
- 文字コードは、0と1を文字に対応づけるルール
- テキストファイルは、すべて文字コードで解釈できる。
- バイナリファイルは、文字コードで解釈できない部分を含む。
- ファイル形式の違いは「解釈のルール」の違い。
この理解があると、
ファイル入出力や文字化けの原因も、
自然と見えてくるようになりますよ。