
C言語入門|終端喪失によるオーバーラン
ここまでで、私たちは C言語の文字列について、大切な業界ルールを学んできました。
特に重要なのが、文字列は \0(ヌル文字)で終わるという絶対条件です。
このルールのおかげで、printf や文字列操作関数は、
「どこまでが文字列なのか」を迷わず判断できます。
ところが―
このルールは、同時に 非常に危険な前提 でもあるのです。
本当は怖い「文字列」の業界ルール
文字列の業界ルール第2条を、少し別の角度から読み直してみましょう。
先頭要素から順に1文字ずつ文字コードを格納する。
最後の文字の直後に \0 を置く。
これは裏を返すと、こういう意味になります。
\0 が現れるまで、
文字列処理は止まらない。
つまり、
終端文字が見つからなければ、どこまでも読み続ける
ということです。
たった1行で起きる致命的な事故
次のコードを見てください。
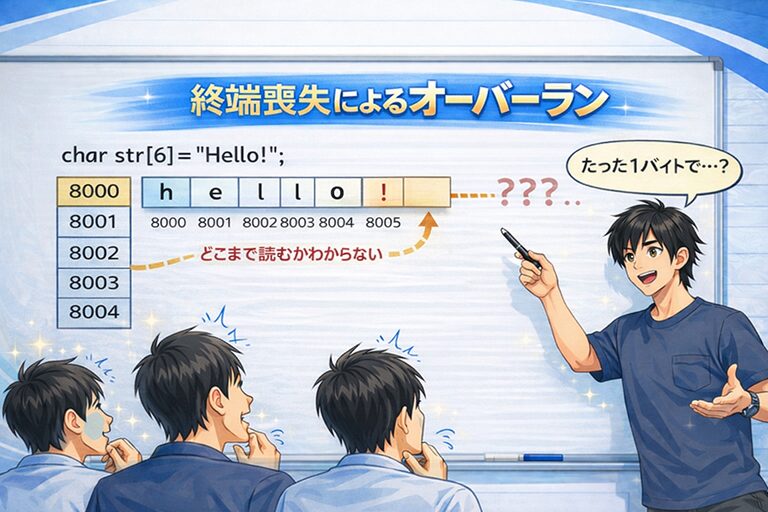
char str[] = "hello";
str[5] = '!';画面に表示したい文字を
「hello!」に変えたかっただけかもしれません。
しかし、この1行が意味することは、想像以上に深刻です。
\0 を失った瞬間、文字列は暴走する
char str[] = "hello";
この時点で、メモリ上は次のようになっています。
| 位置 | 内容 |
|---|---|
| str[0] | 'h' |
| str[1] | 'e' |
| str[2] | 'l' |
| str[3] | 'l' |
| str[4] | 'o' |
| str[5] | \0 |
ところが、str[5] = '!' を実行すると、
| 位置 | 内容 |
|---|---|
| str[5] | '!' |
となり、文字列の終端を示す \0 が消滅します。
これが「終端喪失」です。
printf は止まれなくなる
printf("%s", str); が実行されると、printf はこう考えます。
- 先頭アドレスから文字を表示
- 次の文字を表示
- まだ \0 が出てこない
- では次へ
- 次へ
- 次へ……
\0 が見つかるまで、永遠に進み続ける
それが printf の仕事です。
終端喪失が引き起こすオーバーラン
この状態で起こるのは、単なる表示の乱れではありません。
- 文字列として確保していない領域を読む
- 他の変数の中身を勝手に表示する
- 配列の範囲外にアクセスする
つまり、オーバーラン です。
しかもこれは、
- ポインタ計算のミス
- 添え字の書き間違い
といった「わかりやすいミス」ではなく、
たった1バイトの上書き が原因です。
私たちは「たった1バイト」に守られている
C言語の文字列は、
たった1バイトの \0 によって
世界の終わりを知らされている
と言っても過言ではありません。
この1バイトがある限り、
- 文字列は安全に表示され
- 文字列関数は正しく動き
しかし、この1バイトを失った瞬間、
プログラムは どこまで暴走するかわからない存在 になります。
オーバーランの結末は環境次第
現代の Windows・macOS・Linux などでは、
- メモリ保護機構
- プロセスごとのメモリ分離
があるため、
多くの場合は 異常終了(SEGV) で止まります。
しかし、
- 古い OS
- 組み込み機器
- メモリ保護のない環境
では、話がまったく違います。
- OSの制御情報を書き換える。
- 機器に異常な命令を送る。
- 取り返しのつかない誤動作を起こす。
そんな事故につながる可能性も、決して大げさではありません。
だから文字列は「本当は怖い」
C言語の文字列は便利です。
しかしその便利さは、
プログラマが常に \0 を守る
という前提の上に成り立っています。
- 終端を壊さない。
- 上書きする長さを誤らない。
- コピーや連結の結果を常に意識する。
これらを怠ると、
文字列は最も危険なデータ構造に変貌します。