
C言語入門|11章のまとめ
文字列を「理解して扱える」C言語へ
第11章では、C言語における文字列の正体と、その扱い方を徹底的に掘り下げてきました。
ここまで読み進めたあなたは、もはや
「なんとなく文字列を使っている人」ではありません。
このまとめでは、第11章で学んだ内容を整理しながら、
なぜそれが重要だったのか を改めて確認していきましょう。
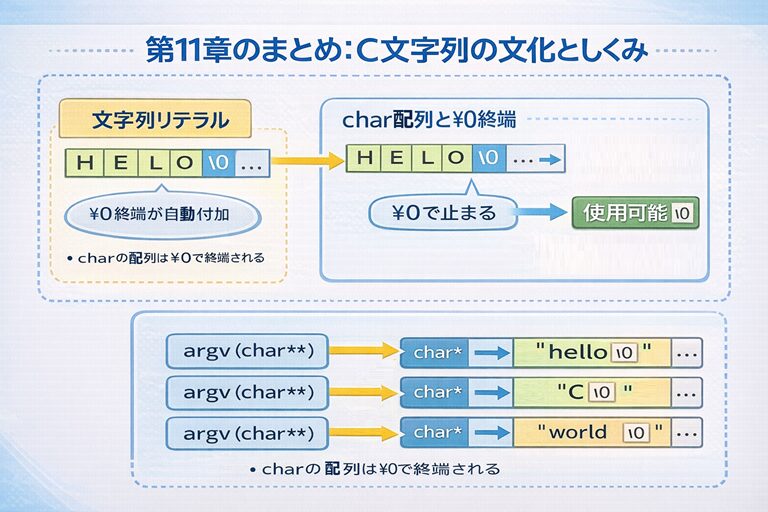
文字列と文化 ― C言語の前提を理解する
C言語において、文字列は特別な型ではありません。
char型の配列や、mallocで確保した連続メモリ領域に
文字コードを並べて格納したもの にすぎません。
ただし、文字列として扱う場合には、
C言語の世界で共有されている重要な約束があります。
| 項目 | 内容 |
|---|---|
| 文字列の実体 | 連続したメモリ領域 |
| 終端 | 最後に必ず文字コード0を置く |
| 利用範囲 | 先頭から最初の0まで |
この
「¥0 に到達するまでが文字列」
という文化があるからこそ、
- printf
- strlen
- strcmp
- strcpy
- strcat
といった標準関数が、共通の前提で動作できるのです。
文字列リテラル ― 見えない¥0の正体
二重引用符で囲まれた文字列リテラルは、
C言語の構文レベルで 自動的に終端文字を付加 してくれます。
char str[] = "hello";
この1行は、次と同じ意味になります。
char str[] = {'h','e','l','l','o','\0'};
要素数を省略した配列宣言と組み合わせることで、
- 終端文字の入れ忘れ
- 要素数不足によるオーバーラン
を防ぎやすくなる、という点も重要でしたね。
オーバーラン ― たった1バイトの怖さ
C言語の文字列は、
¥0 があるかどうか にすべてが依存しています。
終端文字を失った瞬間、
- 表示が止まらない。
- ゴミデータを読み続ける。
- 確保していない領域にアクセスする。
といったオーバーランが発生します。
この章では、文字列を扱うときに
次の3つの領域を常に意識する重要性を学びました。
| 領域 | 意味 |
|---|---|
| 使用中 | 実際に文字列として使っている範囲 |
| 使用可能 | まだ書き込める確保済み領域 |
| 使用禁止 | 絶対に触れてはいけない領域 |
文字列の安全性は、
「見えている文字」ではなく
「見えていないメモリ構造」を理解しているかどうかで決まります。
二重ポインタ ― argvが教えてくれたこと
第11章の最後では、
文字列の配列と二重ポインタという
一見とっつきにくいテーマに挑戦しました。
コマンドライン引数として渡される argv は、
- char*(文字列の先頭アドレス)
- が配列のように並んだ領域
- その先頭アドレス
を表しています。
だから型は char** になる、というわけでした。
| 型 | 意味 |
|---|---|
| char* | 1つの文字列の先頭アドレス |
| char** | char*が並ぶ領域の先頭アドレス |
argvを通して、
- 二重ポインタの考え方
- 文字列の配列の正体
- main関数の特別な役割
を一気に理解できたはずです。
第11章で身についた力
この章を終えた今、あなたは次のことができます。
- 文字列を「配列+終端文字」として説明できる
- なぜオーバーランが起こるのかを構造で理解している
- 文字列操作関数を文化に沿って使い分けられる
- argvや二重ポインタを怖がらずに扱える
これは、C言語を 本気で使うための土台 です。
第11章は、C言語の中でも
事故が起きやすく、同時に最も重要な分野 でした。
ここまで理解できたあなたなら、
次の章以降で扱うより実践的なコードも、
安心して読み進められるはずです。
本当に、おつかれさまでした。