
C言語のきほん|2次元配列の文字列を表示する
2次元配列の1行は、1つの文字列。
その見方が分かると、複数の単語もすっきり表示できる。
C言語では、1つの文字列を char配列で扱います。
そして、複数の文字列をまとめて管理したいときには、2次元配列を使います。
たとえば、果物の名前、都市名、曜日、ユーザー名など、文字列をいくつもまとめて持ちたい場面はよくあります。
そんなときに便利なのが、char型の2次元配列です。
最初は少し不思議に見えるかもしれませんが、考え方はそれほど難しくありません。
2次元配列の 1行ごとに1つの文字列を入れている と考えると、とても分かりやすくなります。
たとえば、次のようなイメージです。
- words[0] は 1つ目の文字列
- words[1] は 2つ目の文字列
- words[2] は 3つ目の文字列
つまり、2次元配列の各行が、それぞれ1本の文字列として使われているわけです。
この見方ができるようになると、複数の文字列を for文で順番に表示する処理がすっと理解できるようになります。
また、printf で %s を使って表示するときは、ただ配列を出力しているのではなく、その行にある文字列の先頭位置から、\0 に出会うまでを文字列として表示している という考え方も大切です。
今はまだ「先頭アドレス」という言葉が少し難しく感じるかもしれませんが、ここではまず、words[i] を指定すると i 行目の文字列を取り出せる と考えておけば大丈夫です。
この記事では、
- 2次元配列で複数の文字列をどう持つのか
- 1行が1つの文字列になるとはどういうことか
- printf の %s でどう表示するのか
- for文を使って順番に表示するにはどう書くのか
といったポイントを、表や例を使いながら丁寧に整理していきます。
2次元配列の各行は1つの文字列
まず、いちばん大事な考え方から確認しましょう。
次のような2次元配列があるとします。
char words[][7] = {"Apple", "Banana", "Cherry"};この配列では、3つの文字列が入っています。
それぞれの行は次のような意味になります。
| 行番号 | 内容 |
|---|---|
| words[0] | Apple |
| words[1] | Banana |
| words[2] | Cherry |
ここでのポイントは、words[0] や words[1] は、1文字ではなく1行分の文字列を表している ことです。
つまり、
- words[0] は A ではなく Apple
- words[1] は B ではなく Banana
- words[2] は C ではなく Cherry
というイメージです。
これは、普通の int型の2次元配列とは少し感覚が違うところです。
int型の2次元配列なら array[0][0] のように1つの数値を見ることが多いですが、char型の2次元配列では 1行全体が1つの文字列になる ので、words[0] のような形でそのまま文字列として扱えるのです。
文字列が2次元配列にどう入っているか
見た目だけでは少し分かりにくいので、内部の並びをイメージしてみましょう。
たとえば次の配列です。
char words[][7] = {"Apple", "Banana", "Cherry"};このとき、各行には次のように文字が並んでいます。
| 行 | [0] | [1] | [2] | [3] | [4] | [5] | [6] |
|---|---|---|---|---|---|---|---|
| words[0] | 'A' | 'p' | 'p' | 'l' | 'e' | '\0' | '\0' |
| words[1] | 'B' | 'a' | 'n' | 'a' | 'n' | 'a' | '\0' |
| words[2] | 'C' | 'h' | 'e' | 'r' | 'r' | 'y' | '\0' |
ここで分かるように、各行はただの文字の並びです。
でも、その行のどこかに \0 が入っているので、C言語ではそこまでを1つの文字列として扱えます。
特に Apple は5文字なので、
- A
- p
- p
- l
- e
- \0
までで文字列が終わります。
行の大きさは7なので、最後にもう1つ \0 が残る形になります。
なぜ %s で words[0] を表示できるのか
次のようなコードがありました。
printf("%s\n", words[0]);
printf("%s\n", words[1]);
printf("%s\n", words[2]);これで、それぞれ Apple、Banana、Cherry が表示されます。
ここで不思議に思いやすいのが、
「words[0] は配列なのに、なぜ %s で表示できるの?」
という点です。
ここではやさしく考えて、words[0] は1行目の文字列の先頭を表している と思えば大丈夫です。
%s は、その先頭から順番に文字を読んでいって、\0 に出会うまでを表示します。
つまり、
- words[0] を渡すと Apple を表示
- words[1] を渡すと Banana を表示
- words[2] を渡すと Cherry を表示
となります。
この考え方は、あとでポインタや文字列処理を学ぶときにもつながっていきます。
今の段階では、2次元配列の1行は %s で表示できる文字列になる と覚えておくと分かりやすいです。
サンプルプログラムで確認してみよう
題材は、3つの都市名を表示するプログラム です。
サンプルプログラム
ファイル名:10_13_1.c
#include <stdio.h>
int main(void)
{
/* 複数の都市名を2次元配列で初期化する */
char cities[][8] = {"Osaka", "Kyoto", "Kobe"};
/* 各都市名を順番に表示する */
for (int i = 0; i < 3; i++) {
printf("%d番目の都市名: %s\n", i + 1, cities[i]);
}
return 0;
}実行結果例
1番目の都市名: Osaka
2番目の都市名: Kyoto
3番目の都市名: Kobeこのプログラムの見方
このプログラムで大切なのは、次の部分です。
char cities[][8] = {"Osaka", "Kyoto", "Kobe"};これは、複数の都市名を2次元配列にまとめて入れています。
| 行番号 | 入っている文字列 |
|---|---|
| cities[0] | Osaka |
| cities[1] | Kyoto |
| cities[2] | Kobe |
そして、for文で i を 0、1、2 と変化させながら、cities[i] を表示しています。
for (int i = 0; i < 3; i++) {
printf("%d番目の都市名: %s\n", i + 1, cities[i]);
}このようにすると、1行目、2行目、3行目の文字列を順番に取り出して表示できます。
列数をどう決めるかがとても大事
2次元配列で文字列を扱うときに、とても大事なのが 列数 です。
たとえば今回の例では、次のように書いています。
char cities[][8] = {"Osaka", "Kyoto", "Kobe"};ここで列数は 8 です。
これは、入れる文字列の中でいちばん長いものと \0 を考えて決めます。
それぞれの長さを確認すると、次のようになります。
| 文字列 | 文字数 | 必要なサイズ |
|---|---|---|
| Osaka | 5 | 6 |
| Kyoto | 5 | 6 |
| Kobe | 4 | 5 |
最長は Osaka と Kyoto の 5文字なので、最低でも 6 必要です。
今回は少し余裕を持って 8 にしています。
ここで列数が足りないと、文字列を正しく格納できないので注意が必要です。
行数は省略できる
今回の宣言では、行数を省略しています。
char cities[][8] = {"Osaka", "Kyoto", "Kobe"};これは、初期化する文字列の個数から自動的に 3 行だと判断されるためです。
ただし、省略できるのは先頭の行数だけです。
列数は、1行あたり何文字入るかを決めるために必要なので、省略できません。
この点を表で整理すると、次のようになります。
| 項目 | 省略できるか |
|---|---|
| 行数 | できる |
| 列数 | できない |
1文字ずつ見るのではなく、1行ずつ見る
2次元配列というと、つい [行][列] の両方を使って細かく見たくなるかもしれません。
もちろんそれもできますが、複数の文字列を表示する場合は、まず 1行を1つの文字列として見る のが基本です。
たとえば、
cities[0]は1文字ではなく、Osaka 全体を表します。
一方で、
cities[0][0]なら O という1文字になります。
この違いはとても大事です。
| 書き方 | 意味 |
|---|---|
| cities[0] | 1行目の文字列全体 |
| cities[1] | 2行目の文字列全体 |
| cities[0][0] | 1行目の1文字目 |
| cities[0][1] | 1行目の2文字目 |
複数の文字列を表示したいときは、cities[i] のように 1行ごと に扱うことがポイントです。
2次元配列の文字列を表示する
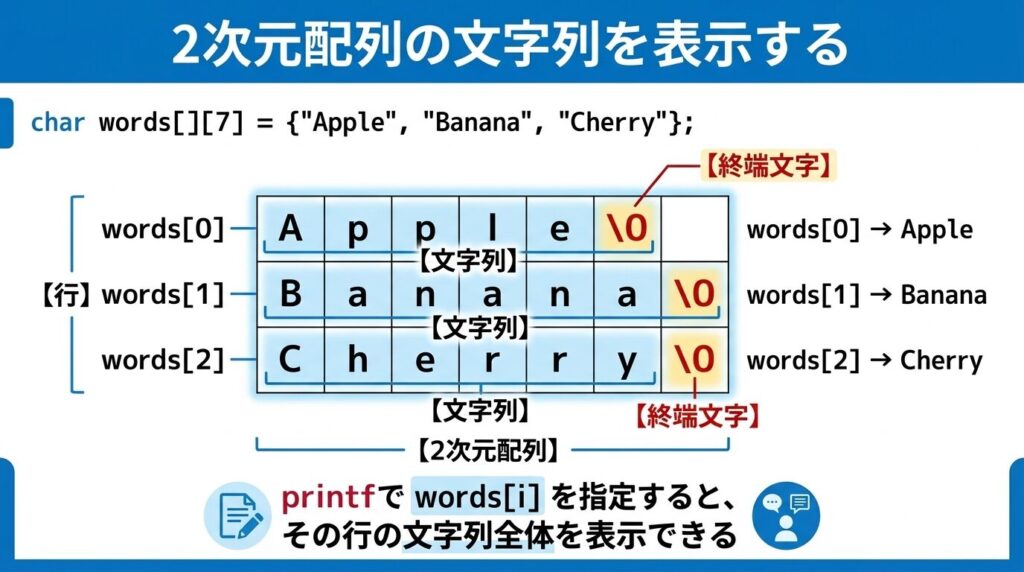
ここでは1カ所だけ図を使うなら、2次元配列の各行が1つの文字列になっていること を表す図がいちばん分かりやすいです。
for文を使うと複数の文字列をまとめて表示できる
1つずつ書いても表示はできます。
printf("%s\n", cities[0]);
printf("%s\n", cities[1]);
printf("%s\n", cities[2]);でも、文字列の数が増えると、この書き方は大変になります。
そこで便利なのが for文です。
for (int i = 0; i < 3; i++) {
printf("%s\n", cities[i]);
}この書き方なら、行数が増えてもすっきり書けます。
2次元配列の「各行を順番に処理する」という考え方にぴったりです。
よくあるつまずきポイント
この内容でよくあるつまずきも整理しておきます。
words[i] と words[i][j] を混同する
これはとてもよくあります。
- words[i] は文字列
- words[i][j] は1文字
ここを取り違えると、%s を使うべきところで %c を使ってしまったり、その逆をしてしまったりします。
列数が足りない
文字列の長さだけでなく、\0 の分も必要です。
たとえば Banana は6文字なので、必要サイズは 7 です。
行数と列数の役割が分からなくなる
2次元配列で文字列を扱う場合は、次のように整理すると分かりやすいです。
| 項目 | 意味 |
|---|---|
| 行数 | 文字列の個数 |
| 列数 | 1つの文字列を入れるための最大サイズ |
もう1つの短い例
最後に、もっと短い例も見ておきましょう。
ファイル名:10_13_2.c
#include <stdio.h>
int main(void)
{
char labels[][6] = {"Red", "Blue", "Green"};
for (int i = 0; i < 3; i++) {
printf("色の名前: %s\n", labels[i]);
}
return 0;
}この例でも、labels[0]、labels[1]、labels[2] はそれぞれ1つの文字列として扱われます。
ただし、この例では Green が5文字なので、\0 を入れると必要サイズは 6 です。
そのため、列数を 6 にしているわけです。
このように考えると、2次元配列に複数の文字列を入れて表示するしくみがかなり見えやすくなってきます。
大切なのは、1行が1つの文字列 という見方をしっかり持つことです。
それが分かると、printf で %s を使った表示も、for文で順番に処理する流れも自然に理解できるようになります。