
C言語のきほん|文字と文字列の違いを理解する
1文字と文章は、見た目は似ていても中身は別もの。
文字と文字列の違いを知ると、C言語の理解がぐっと深まる。
C言語を学び始めると、早い段階で出会うのが 文字 と 文字列 です。
どちらも画面に表示できるので、最初のうちは「どちらも文字の集まりなのだから、同じようなものでは?」と感じやすいところです。
でも、C言語ではこの2つははっきり別のものとして扱われます。
- 文字は char型で扱う
- 文字列は char型の配列で扱う
ここをあいまいなままにしてしまうと、あとで printf や scanf、文字列操作、配列、ポインタの学習に進んだときに混乱しやすくなります。
逆に、ここをしっかり理解しておくと、C言語らしいデータの扱い方がとてもよく見えてきます。
特にC言語は、ほかの言語のように「文字列型」が最初から独立して用意されているわけではありません。
その代わりに、char型の配列を使って文字列を表現するという仕組みになっています。
この仕組みは最初は少し独特に見えますが、メモリ上でどのように文字が並んでいるかを意識しやすく、C言語の学習ではとても大切な考え方です。
この記事では、
- 文字とは何か
- 文字列とは何か
- 文字と文字列は何が違うのか
- なぜ文字列の最後に \0 が必要なのか
- char型変数と char型配列はどう違うのか
といったポイントを、表やイメージを交えながら丁寧に整理していきます。
見た目はよく似ていても、1文字を入れる箱 と 複数文字を順番に入れる箱 では役割がまったく違います。
この違いが分かるようになると、文字列の表示や入力だけでなく、配列やメモリの理解にもつながっていきます。
文字とは何か
まずは 文字 から見ていきましょう。
C言語で文字は、char型 で扱います。
文字というのは、その名の通り 1つだけの文字 を表すデータです。
たとえば次のようなものです。
- A
- 9
- !
- x
C言語では、このような1文字を 文字定数 として書くとき、シングルクォーテーションで囲みます。
char ch1 = 'A';
char ch2 = '9';
char ch3 = '!';ここで大事なのは、1つの文字だけを扱っているという点です。
char型変数のイメージ
| 変数名 | 入っている値 | 意味 |
|---|---|---|
| ch1 | 'A' | A という1文字 |
| ch2 | '9' | 9 という1文字 |
| ch3 | '!' | ! という1文字 |
char型変数は、1文字を保存するための箱、と考えると分かりやすいです。
文字列とは何か
次に 文字列 を見ていきます。
文字列は、複数の文字が並んだデータです。
たとえば次のようなものが文字列です。
- ABC
- Hello
- C言語
- 12345
C言語では、文字列を char型の配列 で扱います。
つまり、文字列は「char型の値が並んだもの」として表現されます。
たとえば次のように書きます。
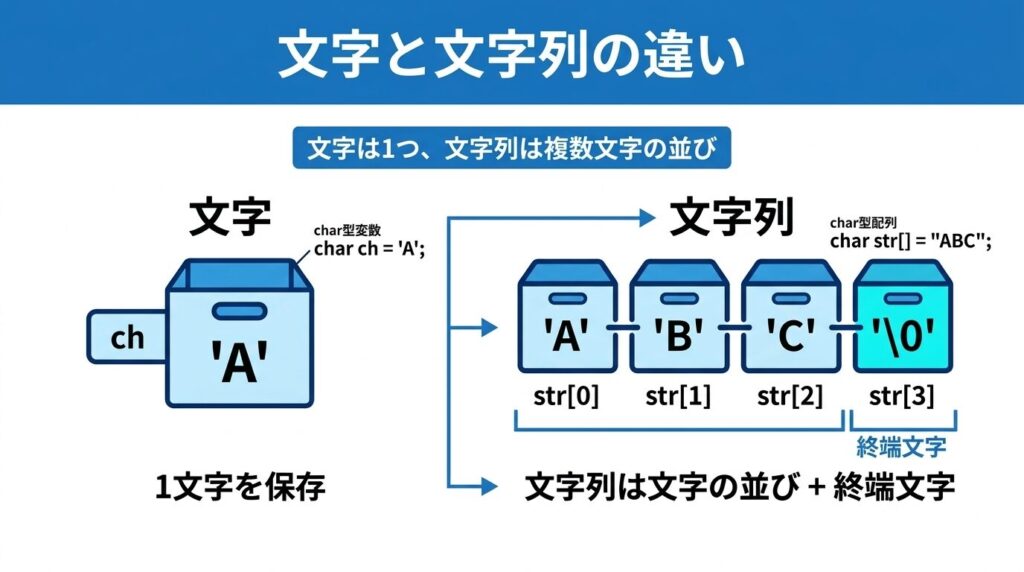
char str[] = "ABC";これは、A、B、C という3つの文字を並べた文字列です。
ただし、C言語ではここで終わりではありません。
文字列の最後には、ナル文字 と呼ばれる特別な文字が自動的に追加されます。
'\0'この \0 は「ここで文字列が終わります」という目印です。
コンピュータはこの目印を見て、文字列の終わりを判断しています。
文字列の中身を1文字ずつ見るとどうなるか
たとえば、次の文字列を考えます。
char str[] = "ABC";見た目では 3文字 ですが、メモリ上では次のように並びます。
| 配列要素 | 入っている値 |
|---|---|
| str[0] | 'A' |
| str[1] | 'B' |
| str[2] | 'C' |
| str[3] | '\0' |
つまり、文字列 "ABC" を保存するには、3文字分ではなく4バイト分の領域が必要になります。
ここはとても重要です。
文字列は単なる文字の並びではなく、最後に終端を表す \0 を持つデータとして扱われます。
文字と文字列の違い
ここまでの内容を、分かりやすく表に整理してみます。
| 項目 | 文字 | 文字列 |
|---|---|---|
| 意味 | 1つの文字 | 複数の文字の並び |
| 主な型 | char型 | char型の配列 |
| 書き方 | 'A' | "ABC" |
| 囲み方 | シングルクォーテーション | ダブルクォーテーション |
| メモリ上の扱い | 1文字分 | 文字の並び + \0 |
| 例 | 'X' | "XYZ" |
この表を見ると、見た目は少し似ていても、C言語ではまったく別のものとして扱っていることが分かります。
特に初心者のうちは、次の違いを意識しておくと整理しやすいです。
- 'A' は文字
- "A" は文字列
この2つは見た目がかなり似ていますが、意味は違います。
| 書き方 | 種類 | 中身 |
|---|---|---|
| 'A' | 文字 | A という1文字 |
| "A" | 文字列 | A と \0 の並び |
" A " のような文字列は、1文字しか見えていなくても、実際には 2つの要素を持つデータ です。
この感覚は、あとで strlen や strcpy などの文字列処理を学ぶときにとても大切になります。
サンプルプログラムで確認してみよう
ここでは、元の説明内容をもとにしながら、もっとシンプルで親しみやすい別の例に置き換えて見ていきます。
表示するメッセージも日本語に変え、コメントも日本語にしています。
サンプルプログラム
ファイル名:10_11_1.c
#include <stdio.h>
int main(void)
{
/* 1文字を保存する変数 */
char mark = 'K';
/* 文字列を保存する配列 */
char name[] = "Kumo";
printf("文字の表示: %c\n", mark);
printf("文字列の表示: %s\n", name);
return 0;
}実行結果例
文字の表示: K
文字列の表示: Kumoこのプログラムで押さえたいポイント
このプログラムは短いですが、文字と文字列の違いがとてもよく分かる例です。
char型変数は1文字を入れる
char mark = 'K';ここでは mark に K という1文字だけを入れています。
そのため、表示するときは %c を使います。
printf("文字の表示: %c\n", mark);%c は「1文字を表示するための書式指定子」です。
char型配列は文字列を入れる
char name[] = "Kumo";こちらは K、u、m、o という複数の文字が並んだ文字列です。
C言語では文字列は char型配列で表します。
表示するときは %s を使います。
printf("文字列の表示: %s\n", name);%s は「文字列を表示するための書式指定子」です。
なぜ文字列は配列なのか
ここはとても大事なところです。
C言語には、最初から独立した「文字列型」がありません。
そのため、文字列は 1文字ずつ並べて保存する という方法で扱います。
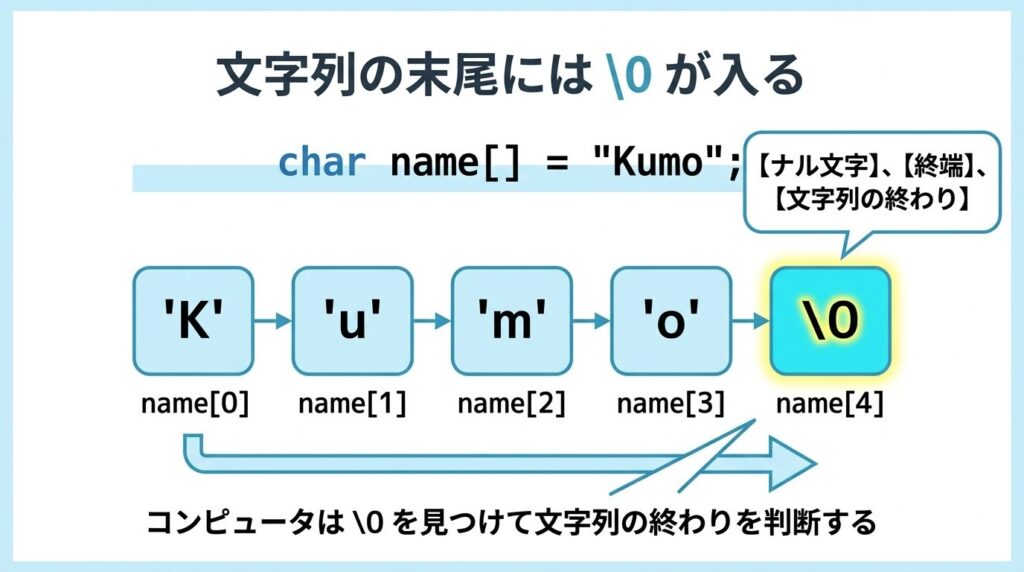
たとえば "Kumo" という文字列は、メモリ上では次のようなイメージです。
| 添字 | 値 |
|---|---|
| name[0] | 'K' |
| name[1] | 'u' |
| name[2] | 'm' |
| name[3] | 'o' |
| name[4] | '\0' |
このように、文字列は 文字の配列 です。
だからこそ、配列の添字を使って1文字ずつ取り出すこともできます。
たとえば次のような書き方ができます。
printf("%c\n", name[0]);
printf("%c\n", name[1]);これで、文字列の中の先頭文字や2文字目を取り出せます。
文字列の終わりを表すナル文字 \0
文字列を理解するとき、いちばん重要なキーワードの1つが ナル文字 です。
ナル文字は次のように表します。
'\0'これは見た目には何も表示されない特別な文字です。
役割はとてもシンプルで、文字列の終わりを知らせることです。
たとえば "ABC" という文字列では、コンピュータは次のように読んでいきます。
- A を読む
- B を読む
- C を読む
- \0 を見つける
- ここで終わりだと判断する
もし \0 がなければ、コンピュータはどこまでが文字列なのか分からなくなってしまいます。
文字列終端のイメージ
このため、文字列を保存する配列を自分で用意するときは、表示したい文字数だけではなく、最後の \0 の分も必要になります。
図で理解すると分かりやすいポイント
文字と文字列の違いは、文章だけでも理解できますが、図があるとかなり整理しやすいです。
特に次の2つは図にすると分かりやすいです。
- char型変数には1文字が入る
- char型配列には文字が順番に並び、最後に \0 が入る
文字と文字列で使う書式指定子も違う
文字と文字列は、表示のしかたも違います。
ここもよく混同しやすいところです。
| データ | 例 | 書式指定子 |
|---|---|---|
| 文字 | mark | %c |
| 文字列 | name | %s |
たとえば、char型変数を %s で表示しようとしたり、文字列を %c で表示しようとすると、正しく動かない原因になります。
この違いは、データの中身が違うからです。
- %c は1文字用
- %s は \0 で終わる文字列用
この対応をセットで覚えておくと安心です。
よくある混乱ポイント
ここでは、初学者が混乱しやすいポイントを整理しておきます。
'A' と "A" は違う
これは本当によく出てくるポイントです。
| 書き方 | 意味 |
|---|---|
| 'A' | 1文字 |
| "A" | 文字列 |
"A" は1文字だけに見えますが、C言語では文字列なので、実際には A と \0 を持っています。
char型変数と char型配列は違う
| 種類 | 例 | 用途 |
|---|---|---|
| char型変数 | char ch = 'A'; | 1文字を保存 |
| char型配列 | char str[] = "ABC"; | 文字列を保存 |
変数1個と配列は、そもそもデータの持ち方が違います。
見た目ではなく中身で考える
画面に表示すると、文字も文字列もどちらも文字として見えます。
でも、C言語では内部の扱いが違います。
- 文字は単独の1文字
- 文字列は複数文字の並び
- 最後に \0 が必要
ここを見た目ではなく、メモリ上でどう保存されているかで考えることが大切です。
1文字ずつ扱えることがC言語らしい強み
C言語では文字列を char型配列で扱うので、文字列の中の1文字ずつを細かく操作しやすいという良さがあります。
たとえば、文字列の先頭文字だけを見る、3文字目を変更する、といった処理もしやすくなります。
char word[] = "cat";
word[0] = 'B';このようにすると、word の中身は Bat になります。
これは、文字列が「文字の配列」として保存されているからできることです。
最初は少し不便に見えるかもしれませんが、この仕組みがあるからこそ、C言語では文字列を柔軟に扱えます。
学習のコツ
文字と文字列の違いをしっかり身につけるには、次の3つを意識すると理解しやすいです。
| 意識すること | 内容 |
|---|---|
| 囲み方を見る | 文字はシングルクォーテーション、文字列はダブルクォーテーション |
| 型を見る | 文字は char型、文字列は char型配列 |
| メモリの並びを考える | 文字列の最後には \0 が付く |
この3つが自然に区別できるようになると、C言語の文字列の学習がかなり進めやすくなります。
もう1つのシンプルなサンプル例
最後に、文字列の中身を1文字ずつ確認できる簡単な例も載せておきます。
ファイル名:10_11_2.c
#include <stdio.h>
int main(void)
{
char text[] = "Hi";
printf("文字列全体: %s\n", text);
printf("1文字目: %c\n", text[0]);
printf("2文字目: %c\n", text[1]);
return 0;
}実行結果例
文字列全体: Hi
1文字目: H
2文字目: iこのプログラムを見ると、文字列全体は %s で表示できる一方、配列の要素を指定すれば1文字ずつ %c で取り出せることが分かります。
この感覚がつかめると、文字列をただの文章としてではなく、文字が並んだ配列として理解できるようになります。