
C言語のきほん|アルゴリズムを支えるデータ構造
速いアルゴリズムは“入れ物”で決まる!データ構造を知ると、処理の設計が一気に上手くなるよ。
アルゴリズムは「手順書」だけど、手順だけではうまく動きません。
なぜなら、手順が扱う対象であるデータには「並び方」や「取り出し方」が必要だからです。
そこで登場するのが データ構造。
データ構造は、データを効率よく管理するための“入れ物とルール”で、アルゴリズムがきちんと働くための土台になります。
たとえば、並べ替え(ソート)をするとき、カードを一列に並べた状態をそのまま扱えると便利ですよね。C言語ならこの“並び”を表現するのに 配列 がぴったりです。
アルゴリズムとデータ構造はセットで考えると理解が進みやすいので、ここでしっかり整理していきましょう。
アルゴリズムとデータ構造の関係
アルゴリズムが「どう処理するか(手順)」なら、データ構造は「どう持つか(形)」です。
データ構造(入れ物・並び・取り出しルール)
↓
アルゴリズム(手順)
↓
速さ・読みやすさ・作りやすさが決まる
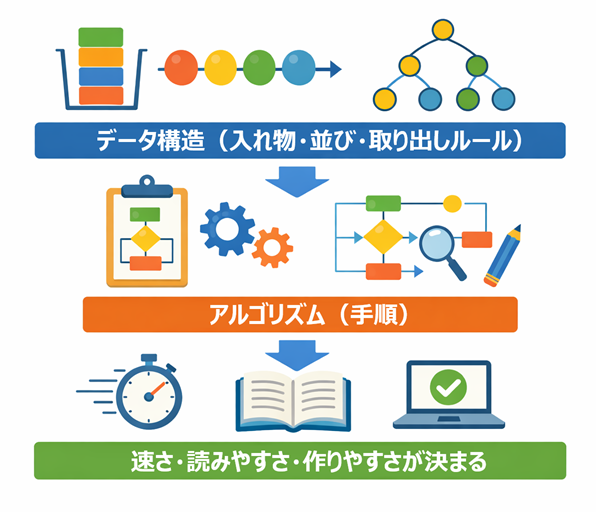
同じ目的でも、入れ物が違うと手順が変わります。
たとえば「先頭のデータを取り出したい」なら、キューが自然だし、「最後に入れたものを戻したい」ならスタックが自然です。
C言語でまず押さえる基本のデータ構造(3つ)
文書の内容をベースに、C言語で最初に扱いやすい3つを整理します。
| 種類 | 何を持つ? | イメージ | 例 |
|---|---|---|---|
| 変数 | 1つの値 | 1つだけ入る箱 | 1人の点数、温度 |
| 配列 | 同じ型の値が複数 | 本棚に同じ種類を並べる | 30人分の点数 |
| 構造体 | 異なる型をひとまとめ | ひとつの棚にセットで保管 | 名前+年齢+身長 |
配列と構造体はこのあと学ぶ予定でも、今の段階で「どういう役割か」を掴んでおくと、アルゴリズムの話が理解しやすくなります。
変数:最小単位の入れ物
変数は一番基本のデータ構造です。
「1つの値だけ」を持つ箱なので、管理が簡単です。
例:1人の点数
ファイル名:7_2_1.c
#include <stdio.h>
int main(void)
{
int score = 82; /* 1人分の点数を入れておく箱 */
printf("今回の点数は%d点です。\n", score);
printf("メッセージ: 変数は1つの値をしまう基本の入れ物だよ。\n");
return 0;
}配列:同じ種類をまとめて扱う
配列は「同じ型」を並べて持てるので、アルゴリズムと相性が抜群です。
ソート、最大値・最小値探し、合計・平均など、定番処理の多くは配列でやります。
例:5人分の点数(合計と平均)
サンプルを“並べ替え”ではなく、まずは分かりやすい集計に置き換えます。
ファイル名:7_2_2.c
#include <stdio.h>
int main(void)
{
int scores[] = {72, 88, 91, 64, 79};
int n = 5;
int i;
int sum = 0;
double avg;
for (i = 0; i < n; i++) {
sum += scores[i];
}
avg = (double)sum / n;
printf("合計は%d点です。\n", sum);
printf("平均は%.1f点です。\n", avg);
printf("メッセージ: 配列は同じ種類のデータをまとめて扱えるよ。\n");
return 0;
}ここで自然に出てくるのが「繰り返し(for)」です。配列はループとセットで覚えると強いです。
構造体:違う種類を1セットにする
構造体は「人1人分の情報」みたいに、異なる型をまとめて扱いたいときに便利です。
点数だけなら int で足りますが、名前や年齢も扱いたくなった瞬間に構造体が必要になります。
今はイメージだけでOKです。
学生 = { 名前, 年齢, 身長, 体重 }
「1人分のデータのまとまり」を表現するのが構造体、という理解がまず大切です。
代表的なデータ構造(配列や構造体で作れる)
C言語には、スタックやキューが最初から用意されているわけではありません。
でも、配列や構造体、ポインタを使うことで実装できます。
ここでは「どういうルールでデータを出し入れするか」を押さえます。
スタック(LIFO:後入れ先出し)
最後に入れたものが最初に出てくる構造です。
- 本を積んで、上から取る
- 皿を重ねて、上から取る
push(入れる): 上に積む
pop(取り出す): 上から取る
最後に入れたものが最初に出る
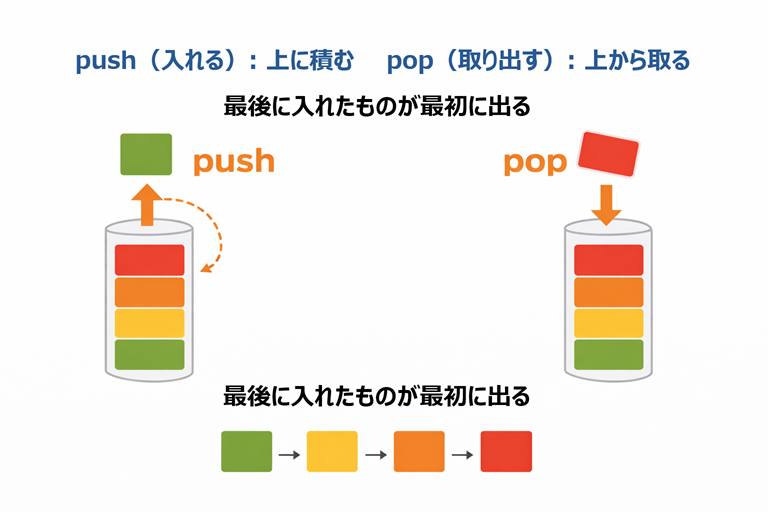
超シンプル例:配列でスタックっぽく
細かい実装は後でもいいので、動きの雰囲気だけ見える例にします。
ファイル名:7_2_3.c
#include <stdio.h>
int main(void)
{
int stack[3];
int top = 0; /* 次に入れる位置 */
/* push */
stack[top++] = 10;
stack[top++] = 20;
stack[top++] = 30;
/* pop */
printf("取り出し1: %d\n", stack[--top]);
printf("取り出し2: %d\n", stack[--top]);
printf("メッセージ: スタックは最後に入れたものが先に出るよ。\n");
return 0;
}キュー(FIFO:先入れ先出し)
最初に入れたものが最初に出てくる構造です。
- レジの待ち行列
- ATMの順番待ち
enqueue(入れる): 後ろに並ぶ
dequeue(取り出す): 前から出る
最初に入れたものが最初に出る
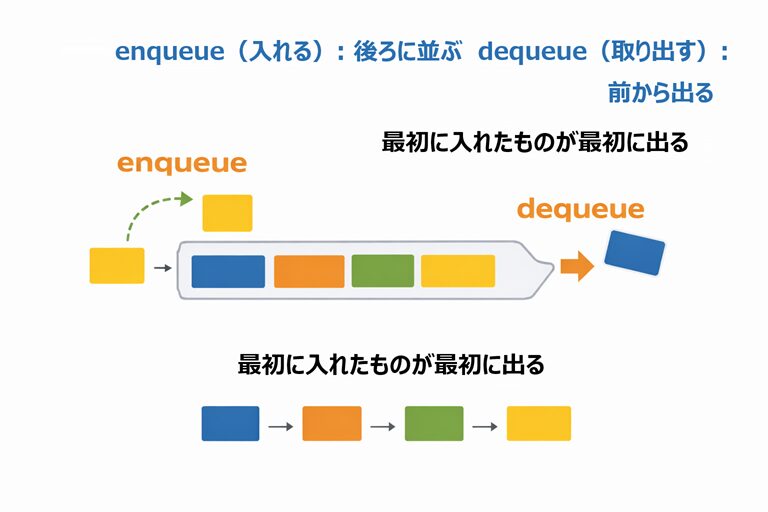
キューは「先頭から取り出す」ので、配列だけでやるとずらしが必要になったりして工夫が増えます。そこがまた面白いところです。
リスト(挿入・削除が得意)
配列は連続して並んでいるので、途中に追加・削除をすると要素をずらす必要があります。
リストは「つながり」で管理するので、途中の挿入・削除が得意になります。
- To-Do リスト
- 再生リスト
というイメージが近いです。
ハッシュ(検索が速い)
ハッシュは「キー → 値」を高速に引ける仕組みです。
- 名前 → 電話番号
- 単語 → 意味
みたいな「探す」が強い構造です。
アルゴリズムとしては、検索や登録が速くなるのが魅力です。
木(ツリー:階層構造)
階層で管理するデータ構造です。
- フォルダ構造
- 組織図
親子関係があるデータを扱うときに強いです。
どれを使えばいい?(入れ物選びの考え方)
迷ったら「何が多い作業か」で選ぶとスッキリします。
| やりたいこと | 向いている構造の例 |
|---|---|
| まとめて並べて順番に見る | 配列 |
| 最後に入れたものを戻す | スタック |
| 先に入れた順に処理する | キュー |
| 途中の追加・削除が多い | リスト |
| キーで高速検索したい | ハッシュ |
| 階層で管理したい | 木 |
この考え方ができるようになると、「アルゴリズムを選ぶ」だけじゃなく「データの持ち方を選ぶ」設計力が育ってきます。