
C言語基礎|関連データをまとめる構造体
「バラバラ管理、もう限界。構造体で“ひとまとまり”にして、ミスを消そう。」
ポインタや文字列を学んできたところで、次の“山場”が構造体です。
でも怖がらなくて大丈夫。構造体は一言でいうと 「同じ対象に属するデータを、1つの箱にまとめて扱うしくみ」 です。
たとえば「社員」という対象があるなら、
- 社員ID(int)
- 氏名(char 配列)
- 部署(char 配列)
- 評価点(int)
みたいに、型が違うデータがセットで付いてきますよね。
これを「配列を何本も作って、同じ添字で対応付ける」方式で管理すると、規模が増えた瞬間に事故ります。
- 交換(swap)を1本だけ忘れて、データがズレる
- 添字の意味が分からなくなる
- 修正のたびに、修正箇所が増殖する
そこで「最初から“関連している”ことをプログラム上でも表現しよう」というのが、構造体の出番です。
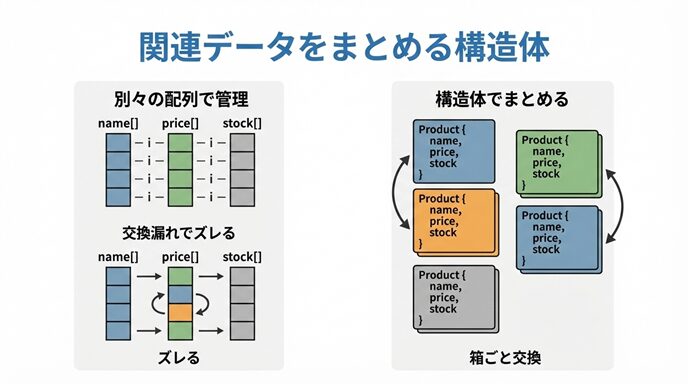
まずは「配列を複数持つ管理」がなぜ危ないのか
ありがちな管理方法(ズレやすい)
「商品」を管理するとして、別々の配列を用意する例です。
| データ | 例 | 型 | 管理方法 |
|---|---|---|---|
| 商品名 | "りんご" | 文字列 | names[i] |
| 価格 | 120 | int | prices[i] |
| 在庫 | 30 | int | stocks[i] |
この方式のルールは「同じ i が同じ商品」という暗黙の約束。
でも、ソートや入れ替えをするときに 1つでも交換を忘れたら破綻します。
図:添字の対応がズレると何が起きる?
ソート前(対応が正しい)
| i | names[i] | prices[i] | stocks[i] |
|---|---|---|---|
| 0 | りんご | 120 | 30 |
| 1 | みかん | 80 | 50 |
| 2 | ばなな | 150 | 20 |
価格でソートしたいのに、prices だけ入れ替えた(事故)
| i | names[i] | prices[i] | stocks[i] |
|---|---|---|---|
| 0 | りんご | 80 | 30 |
| 1 | みかん | 120 | 50 |
| 2 | ばなな | 150 | 20 |
もうこの時点で「りんごの価格が80円」みたいな嘘データになります。
こういう“整合性崩壊”が、配列分割管理の最大の弱点です。
解決策:構造体で「1件のデータ」を1つにまとめる
構造体は「関連データをまとめた新しい型」を作れます。
構造体は「1レコード=1箱」
- 商品1件を struct Product にまとめる。
- 配列にするなら Product products[個数] とできる。
- 入れ替えは「箱ごと」交換すれば整合性が保てる。
| 1箱(1商品) | 中身 |
|---|---|
| Product | name / price / stock |
サンプルプログラム:構造体で商品一覧を価格順に並べ替える(バブルソート)
プロジェクト名:chap12-1-1 ソースファイル名:chap12-1-1.c
#include <stdio.h>
#include <string.h>
#define COUNT 5
#define NAME_LEN 32
typedef struct {
char name[NAME_LEN];
int price;
int stock;
} Product;
// 2つのProductを交換する
void swap_product(Product *a, Product *b)
{
Product temp = *a;
*a = *b;
*b = temp;
}
// priceの昇順で並べ替える(バブルソート)
void sort_by_price(Product items[], int n)
{
for (int i = 0; i < n - 1; i++) {
for (int j = n - 1; j > i; j--) {
if (items[j - 1].price > items[j].price) {
swap_product(&items[j - 1], &items[j]);
}
}
}
}
int main(void)
{
Product items[COUNT] = {
{"りんご", 120, 30},
{"みかん", 80, 50},
{"ばなな", 150, 20},
{"ぶどう", 300, 10},
{"もも", 200, 15}
};
puts("現在の一覧です。");
for (int i = 0; i < COUNT; i++) {
printf("%d: %-6s 価格=%3d円 在庫=%2d\n",
i + 1, items[i].name, items[i].price, items[i].stock);
}
sort_by_price(items, COUNT);
puts("\n価格の安い順に並べ替えました。");
for (int i = 0; i < COUNT; i++) {
printf("%d: %-6s 価格=%3d円 在庫=%2d\n",
i + 1, items[i].name, items[i].price, items[i].stock);
}
return 0;
}この例のポイント(何が嬉しい?)
- 並べ替えの交換は swap_product 1回だけ
→ 名前・価格・在庫が 必ずセットで動く - 「同じ添字が同じ商品」という暗黙ルールが薄れる
→ items[i] が「商品1件」そのもの
文書中の「各項目」を表と図でしっかり解説
➀ データの関連性とは?
“同じ対象に属するデータ同士のつながり”です。
学生なら「名前・身長・体重」、商品なら「商品名・価格・在庫」みたいに、一緒に動くべき情報のこと。
| 対象 | 関連データの例 | 一緒に動く理由 |
|---|---|---|
| 学生 | 名前 / 身長 / 体重 | 同一人物の属性だから |
| 商品 | 商品名 / 価格 / 在庫 | 同一商品の属性だから |
| 社員 | 社員番号 / 部署 / 評価 | 同一社員の属性だから |
説明(表の意味)
左列の「対象」が“主語”で、真ん中が“持っている属性”。右列が“なぜセットか”です。ここが腹落ちすると、構造体の必要性が自然に見えてきます。
➁ バブルソートがやっていること(隣同士を比較して必要なら交換)
本文にあった「赤色の部分=隣り合う2要素の判定と交換」は、バブルソートの核です。
| 手順 | 何をする? | 目的 |
|---|---|---|
| 比較 | items[j-1] と items[j] の価格を比べる | 順序が正しいか確認 |
| 交換 | 逆なら2つを入れ替える | 小さい値を前へ送る |
| 繰り返し | 右から左へ、何度も行う | 全体を整列させる |
説明(表の意味)
比較→交換→繰り返し、が“泡(bubble)”みたいに小さい値が左へ浮かんでいく動きになります。
➂ 「交換を関数に依頼する」意味(swap の重要性)
交換処理はミスが起きやすいので、関数にまとめると安全です。
配列を複数持つ方式だと、swap_int / swap_str / swap_double…と増殖していきます。
| 管理方式 | 交換に必要なもの | 増えるとどうなる? |
|---|---|---|
| 配列を別々に管理 | 型ごとのswap関数、交換の呼び出し漏れ対策 | 漏れた瞬間に整合性崩壊 |
| 構造体でまとめる | swap_product 1つ | 交換漏れが起きにくい |
説明(表の意味)
「関数が増える」のが問題というより、「交換を忘れる余地」が増えるのが本質的な問題です。構造体は“忘れる余地”そのものを減らします。
登場する命令(ここでは関数)の書式と役割
※C言語の文脈では「命令=関数や構文」として扱い、ここで出てきたものを整理します。
swap_product の書式と役割
| 項目 | 内容 |
|---|---|
| 書式 | void swap_product(Product *a, Product *b) |
| 役割 | 2つのProduct(商品データ)を丸ごと入れ替える |
| ポイント | ポインタで受け取るので、呼び出し元の配列要素が直接入れ替わる |
説明
a と b は「商品の箱」の住所です。中身を temp に退避して入れ替えています。箱ごと動くので、関連データが絶対にズレません。
sort_by_price の書式と役割
| 項目 | 内容 |
|---|---|
| 書式 | void sort_by_price(Product items[], int n) |
| 役割 | items を価格の昇順に並べ替える |
| アルゴリズム | バブルソート |
| 比較条件 | items[j - 1].price > items[j].price |
説明
items[j].price のように、構造体の中身へは . でアクセスします。配列要素そのものを交換するので、データ整合性を保ったまま並べ替えられます。
よく出る記号もここで整理(. と &)
| 記号 | 例 | 意味 |
|---|---|---|
| . | items[i].price | 構造体のメンバにアクセス |
| & | &items[j] | 変数のアドレス(住所)を取得 |
説明
交換関数は Product * を受け取るので、配列要素の住所を & で渡します。これが「呼び出し元を書き換える」基本テクです。