
C言語基礎|文字列のコピー
ポインタを1文字ずつ進めるだけ!―C流の高速・美しい文字列コピーを体に覚えよう。
文字列を扱っていると、「別の配列へコピーしたい」場面が必ず出てきます。
たとえば、入力を一旦バッファに受けてから本体へ反映したり、加工用の作業領域へ移したりですね。
ここで大事なのは、C言語の文字列は**'\0'(ナル文字)で終わる char の並び**だということ。
コピーも結局は、
- 先頭から1文字ずつ
- '\0' が出るまで
- コピー先へ代入しながら進む
というシンプルな繰り返しになります。
この「1文字ずつ進む」を、添字ではなくポインタの増分(++)で書くのが、C熟練者っぽい書き方です。
サンプルプログラム
ご指定どおり、元の ABC やメッセージを使わず、別の日本語メッセージに置き換えたシンプル例です。
プロジェクト名:chap11-5-1 ソースファイル名:chap11-5-1.c
Visual Studio でこのプログラムを実行するには、SDLチェック設定を変更しておく必要があります。
1.プロジェクト名を右クリックして、「プロパティ」をクリックします。
2.「C/C++」→「全般」→「SDLチェック」を「いいえ」に切り替えて「OK」をクリックします。
#include <stdio.h>
// 文字列srcをdstにコピーする(dstを返す)
char *str_copy(char *dst, const char *src)
{
char *top = dst;
while (*dst++ = *src++) {
// 代入が0('\0')になるまで続く
}
return top;
}
int main(void)
{
char text[128] = "はじめの文字列";
char buf[128];
printf("現在の text:%s\n", text);
printf("新しく入れたい言葉:");
scanf("%127s", buf);
str_copy(text, buf);
printf("更新後の text:%s\n", text);
return 0;
}まず押さえる:文字列コピーがやっていること
コピー処理の全体像
| 要素 | 内容 |
|---|---|
| コピー元 | src が指す文字列(先頭から '\0' まで) |
| コピー先 | dst が指す配列領域(十分なサイズが必要) |
| 繰り返し | 1文字コピー → ポインタを進める |
| 終了条件 | '\0' をコピーした瞬間に止まる(終端もコピーする) |
表の説明
- 「終端の '\0' もコピーする」のが超重要です。これがないとコピー先が文字列になりません。
関数 str_copy の引数と返り値
関数の書式
- 書式:char *str_copy(char *dst, const char *src);
引数の意味
| 引数 | 型 | 意味 | 変更される? |
|---|---|---|---|
| dst | char * | コピー先の先頭を指すポインタ | 中身(配列の内容)が書き換わる |
| src | const char * | コピー元の先頭を指すポインタ | 中身は変更しない約束 |
表の説明
- const char * は「コピー元は読むだけだよ」という安全宣言です。
- dst の中身を書き換えるので dst 側は const を付けません。
返り値 char * が返すもの
この関数は top(コピー先の先頭アドレス) を返します。
途中で dst はどんどん進んでしまうので、先頭を覚えておくために top を使います。
while (*dst++ = *src++) の“2段階”を分解する
ここがこの記事の核心です。短い式に見えますが、やっていることは筋が通っています。
*dst++ = *src++ の評価の流れ
| 段階 | 起きること | 重要ポイント |
|---|---|---|
| ① 代入 | *dst = *src が実行される | src が指す1文字を dst へコピー |
| ② 増分 | dst と src がそれぞれ1つ進む | 次の文字へ移動する |
| ③ 条件判定 | 代入式の結果(代入した文字)で while を判定 | 代入した文字が '\0' なら終了 |
表の説明
- while の条件は「代入式そのもの」です。
- Cでは代入式の値は「代入後の左辺の値」になります。
つまり、コピーした文字が '\0'(数値として0)になった瞬間に while が終わります。
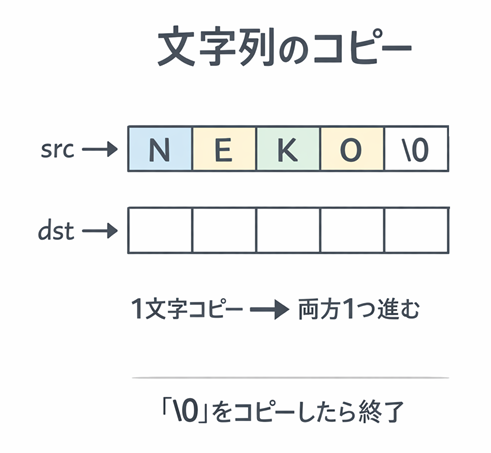
図でつかむ:コピーが進む様子
例として src が "NEKO" のときの流れです。
1文字ずつコピーし、'\0' で止まる
src: 'N' 'E' 'K' 'O' '\0'
↑
src
dst: [ ] [ ] [ ] [ ] [ ]
↑
dst
1回目: 'N' をコピー → 両方進む
2回目: 'E' をコピー → 両方進む
3回目: 'K' をコピー → 両方進む
4回目: 'O' をコピー → 両方進む
5回目: '\0' をコピー → 条件が0 → ループ終了
図の説明
- コピーは「見える文字」だけじゃなく、最後の '\0' も含めて完成します。
- '\0' をコピーした瞬間に終了するので、ちょうどよく止まります。
添字で書く別解との比較(なぜポインタ版が好まれる?)
添字版(わかりやすい形)だと、だいたいこうなります。
int i = 0;
while (dst[i] = src[i]) {
i++;
}
添字版とポインタ版の違い
| 観点 | 添字版 | ポインタ版 |
|---|---|---|
| 追加変数 | i が必要 | 不要 |
| 参照の形 | dst[i], src[i] | *dst, *src |
| 進め方 | i を増やす | ポインタを増やす |
| 書き味 | 明快だけど少し長い | 短くてCらしい |
表の説明
- 添字版は読みやすいです。最初はこれでもOK。
- ポインタ版は「加算して参照外し」を毎回書かずに済む分、コードが締まります。
(実際の最適化はコンパイラがやるので、必ず速いと断言はしないけど、意図としては効率的になりやすい、という理解でOKです。)
登場する命令(関数)の書式と役割
scanf
- 書式:scanf(書式文字列, 格納先...);
- 何をする命令?:標準入力から読み取り、指定した場所へ格納する
- 今回のポイント:%127s
・buf は 128 文字分の配列
・最大127文字を読み、最後に '\0' を付ける余裕を確保(安全策)
printf
- 書式:printf(書式文字列, 引数...);
- 何をする命令?:指定した形式で表示する
注意点(実務で事故りやすいところ)
よくある落とし穴
| 落とし穴 | 何が起きる? | 対策 |
|---|---|---|
| dst の領域が小さい | はみ出してメモリ破壊 | コピー先サイズを確保する |
| src と dst が重なる | 途中で壊れたコピーになることがある | 重なる可能性があるなら別手段(memmove系の発想) |
| 文字列リテラルへコピー | 書き込み不可領域で落ちる可能性 | dst は必ず配列など書き込み可能領域にする |
表の説明
- 文字列コピーは「コピー先のサイズ」が命です。ここだけは口酸っぱく言いたいポイントです。