
C言語基礎|構造体の配列
「1人分をまとめたら、次は“みんな分”。構造体の配列でデータ管理が一気に実戦レベル!」
構造体で「1人分」「1商品分」みたいに“まとまり”を作れるようになると、次にやりたくなるのは…そう、複数人分をまとめて扱うことです。
たとえば「商品を10個管理したい」「センサーを5台分まとめたい」みたいな場面では、
構造体を1個ずつ用意していると管理が大変になってきます。
そこで登場するのが 構造体を要素にした配列、つまり 構造体の配列です。
配列なので、添字でアクセスできて、ループで回せて、ソートもできます。
しかも、1要素が “データのまとまり” なので、関連性が崩れにくくてとても素直です。
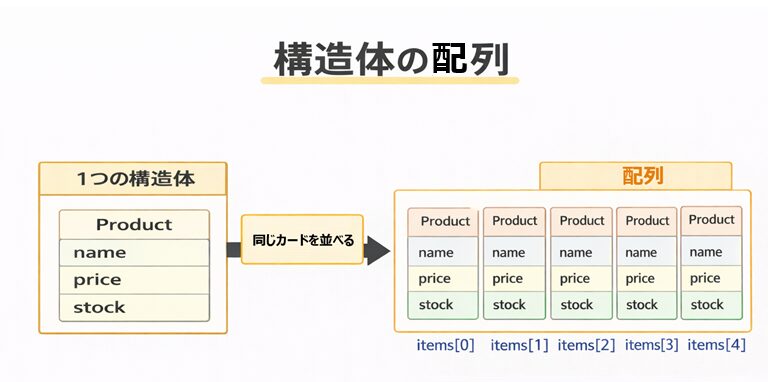
構造体の配列とは?(まずはイメージ)
図:配列の1要素が「カード1枚」
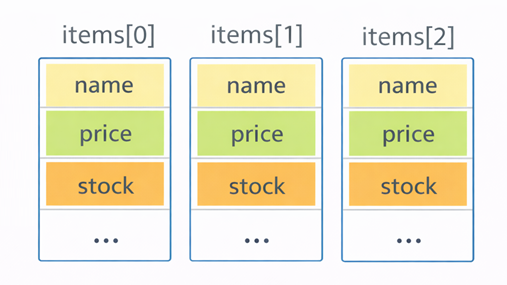
図の説明
- 配列の各要素が、構造体(カード)1枚ぶん
- だから items[i] で「i番目の商品(まとまり)」を取り出せます
なぜ“構造体の配列”が便利なの?
ばらばらの配列で管理すると、対応関係が壊れやすいです。
ばらばら管理 vs まとめ管理
| 管理方法 | 例 | 起きがちな問題 |
|---|---|---|
| ばらばらの配列 | names[], prices[], stocks[] | 並び替えでズレやすい、同じ番号が本当に同じ商品か不安 |
| 構造体の配列 | items[] の各要素に name/price/stock | 1要素が1商品なのでズレない、ソートも素直 |
サンプルプログラム
元の「学生を身長順ソート」ではなく、商品リストを価格順にソートする例に変更します。
表示メッセージも別の日本語に置き換えています。
仕様
- 商品(名前・価格・在庫)を構造体で表す
- 商品を複数個、構造体の配列に入れる
- 価格の昇順にソートして表示する
- 交換は swap_Product で「構造体丸ごと」入れ替える
プロジェクト名:chap12-7-1 ソースファイル名:chap12-7-1.c
#include <stdio.h>
#define COUNT 5
#define NAME_LEN 32
typedef struct {
char name[NAME_LEN]; // 商品名
int price; // 価格(円)
int stock; // 在庫数
} Product;
// x と y が指す Product を交換する
void swap_Product(Product *x, Product *y)
{
Product temp = *x;
*x = *y;
*y = temp;
}
// 配列 a の先頭 n 個を価格の昇順にソートする(バブルソート)
void sort_by_price(Product a[], int n)
{
for (int i = 0; i < n - 1; i++) {
for (int j = n - 1; j > i; j--) {
if (a[j - 1].price > a[j].price) {
swap_Product(&a[j - 1], &a[j]);
}
}
}
}
int main(void)
{
Product items[] = {
{"りんご", 158, 12},
{"みかん", 120, 30},
{"バナナ", 198, 8},
{"メロン", 980, 2},
{"ぶどう", 398, 5},
};
printf("ソート前の一覧です。\n");
for (int i = 0; i < COUNT; i++) {
printf("%-8s %4d円 在庫%2d\n",
items[i].name, items[i].price, items[i].stock);
}
sort_by_price(items, COUNT);
printf("\n価格順に並べ替えました。\n");
for (int i = 0; i < COUNT; i++) {
printf("%-8s %4d円 在庫%2d\n",
items[i].name, items[i].price, items[i].stock);
}
return 0;
}構造体の配列の宣言と初期化(書式と意味)
書式:構造体配列の宣言
型名 配列名[要素数];
書式:初期化子でまとめて入れる
型名 配列名[] = {
{ ... }, { ... }, ...
};
今回の例の読み方
| 記述 | 意味 |
|---|---|
| Product items[] | Product 型の要素が並ぶ配列 items |
| {"りんご", 158, 12} | 1要素分(1商品のまとまり)を初期化 |
| items[i].price | i番目の商品(items[i])の price メンバ |
メンバアクセス:配列×構造体の書き方
構造体配列ではこの形が定番です。
よく使う形
| 書き方 | 意味 |
|---|---|
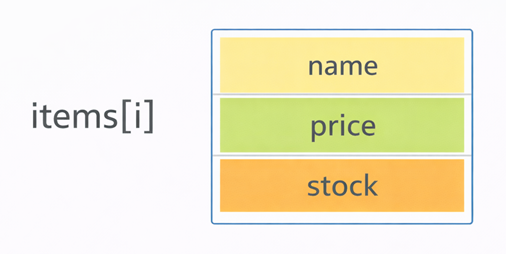
| items[i] | i番目の構造体(商品1つ) |
| items[i].name | i番目の商品の名前 |
| items[i].price | i番目の商品の価格 |
| items[i].stock | i番目の商品の在庫 |
図:items[i] は「1商品カード」
交換関数 swap_Product がラクな理由
構造体の配列を扱うとき、交換(入れ替え)は超よく出ます。
ここで「構造体は代入できる」という性質が効いてきます。
交換の考え方
| 方法 | 何を交換する? | 大変さ |
|---|---|---|
| ばらばら管理 | 名前配列も価格配列も在庫配列も全部交換 | ミスりやすい |
| 構造体配列 | Product を丸ごと交換 | 1回で済む |
swap_Product の中身(読み方)
Product temp = *x;
*x = *y;
*y = temp;
- x と y は Product へのポインタ
- *x と *y は「その場にある Product 実体」
- 代入で丸ごとコピーできるので、交換がスッキリします
ソート関数 sort_by_price の見どころ
この例のソートは「バブルソート」系の形です。
書式:配列を受け取る関数
void sort_by_price(Product a[], int n)
何をする命令?
- Product の配列 a の先頭 n 個を、価格の昇順に並べ替えます。
- a[] という形は「配列を受け取っている」ように見えますが、実際には 先頭要素へのポインタとして扱われます。
- そのため、関数内で a の要素を入れ替えると、呼び出し側の配列も並び替わります。
図:関数は配列の先頭を受け取って並べ替える
main の items[0] ──→ sort_by_price の a[0]
main の items[1] ──→ sort_by_price の a[1]
...
(同じ配列を見ている)
派生型(derived type)の話をやさしく整理
C言語は「型を組み合わせて新しい型を作る」のが得意です。
構造体の配列は、まさに “構造体” と “配列” の合体ですね。
代表的な派生型(今回の範囲で押さえたい)
| 派生型 | 何を作る? | イメージ |
|---|---|---|
| 配列型 | 同じ要素型がずらっと並ぶ | a[10] |
| 構造体型 | いろいろな型をひとまとめ | struct |
| ポインタ型 | どこかを指す型 | int *p |
| 関数型 | 引数と戻り値で決まる型 | int f(int) |
図:構造体の配列は「派生の合体」
Product(構造体型)
↓ を要素にして
Product items[5](配列型)
演習問題
演習12-4
上の「商品を価格順にソートするプログラム」を、次のように書き換えてください。
- 商品データは初期化子で与えず、キーボードから読み込む
- 価格の昇順にソートするか、名前の昇順にソートするかを選べるようにする
(選択は 1:価格 / 2:名前 のような入力でOK)
解答例(そのまま動く版)
プロジェクト名:chap12-7-2 ソースファイル名:chap12-7-2.c
#include <stdio.h>
#include <string.h>
#define COUNT 5
#define NAME_LEN 32
typedef struct {
char name[NAME_LEN];
int price;
int stock;
} Product;
void swap_Product(Product *x, Product *y)
{
Product temp = *x;
*x = *y;
*y = temp;
}
void sort_by_price(Product a[], int n)
{
for (int i = 0; i < n - 1; i++) {
for (int j = n - 1; j > i; j--) {
if (a[j - 1].price > a[j].price) {
swap_Product(&a[j - 1], &a[j]);
}
}
}
}
void sort_by_name(Product a[], int n)
{
for (int i = 0; i < n - 1; i++) {
for (int j = n - 1; j > i; j--) {
if (strcmp(a[j - 1].name, a[j].name) > 0) {
swap_Product(&a[j - 1], &a[j]);
}
}
}
}
int main(void)
{
Product items[COUNT];
for (int i = 0; i < COUNT; i++) {
printf("商品%dの名前:", i + 1);
scanf("%s", items[i].name);
printf("商品%dの価格:", i + 1);
scanf("%d", &items[i].price);
printf("商品%dの在庫:", i + 1);
scanf("%d", &items[i].stock);
}
int mode;
printf("\n並べ替え方法を選んでください(1:価格 2:名前):");
scanf("%d", &mode);
if (mode == 1) {
sort_by_price(items, COUNT);
printf("\n価格順に並べ替えました。\n");
} else {
sort_by_name(items, COUNT);
printf("\n名前順に並べ替えました。\n");
}
for (int i = 0; i < COUNT; i++) {
printf("%-8s %4d円 在庫%2d\n",
items[i].name, items[i].price, items[i].stock);
}
return 0;
}解説(ポイント)
- 構造体の配列 items[i] に対して、メンバごとに scanf で読み込む。
- sort_by_name では strcmp を使って文字列比較(辞書順)
- 並べ替えの本体は「比較して swap」で共通なので、構造体丸ごと交換が効いてきます。