
C言語基礎|文字コードと数字文字
「見た目は同じ0でも、中身は別モノ!―文字コードを知ると数字処理が一気にラクになる」
文字と数値が“ごっちゃ”になる瞬間を卒業しよう
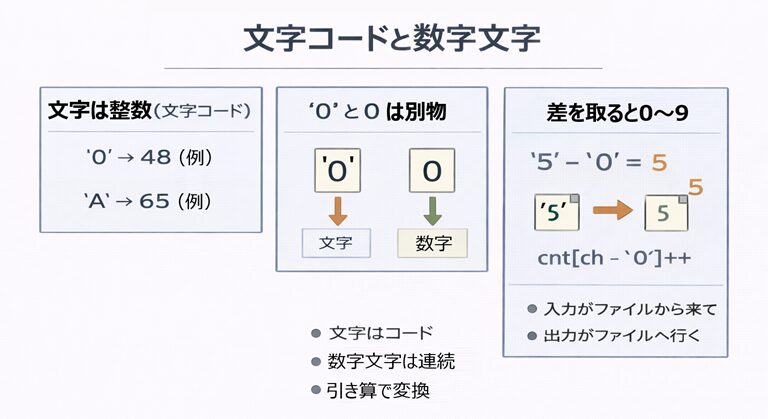
C言語では、文字はただの飾りではなく 整数値(文字コード) として扱われます。
だからこそ、数字の 0 と、文字の '0' は見た目は似ていても まったく別の値 です。
この違いを理解すると、
- 数字文字のカウント
- 文字から数値への変換
- EOF を使った入力終了判定
がスムーズにつながります。
この記事では、元の「EOF と '0'〜'9' を表示」する例にして、文字コードと数字文字の関係、そして 可搬性(環境が違っても正しく動く) まで丁寧に整理しますね。
文字コードってなに?C言語では文字は整数として扱う
文字は“整数のラベル付き”
'0' という文字 → 内部では整数(文字コード)
'A' という文字 → 内部では整数(文字コード)
図の説明
C言語の式の中で 'A' や '0' を使えるのは、実体が「整数値」だからです。
この整数値を 文字コード と呼びます。
数字文字 '0'〜'9' の文字コード(代表例)
多くの環境では ASCII 互換の並びになっていて、'0'〜'9' は連続した値になります。
数字文字のコード例(ASCII互換)
| 文字 | 16進数 | 10進数 |
|---|---|---|
| '0' | 0x30 | 48 |
| '1' | 0x31 | 49 |
| '2' | 0x32 | 50 |
| '3' | 0x33 | 51 |
| '9' | 0x39 | 57 |
表の説明
ここで大事なのは「数字文字の値が 0〜9 ではない」こと。
文字の '0' は 48(例)で、数値の 0 とは別物です。
EOF も整数:だから getchar の受け取りは int が定番
getchar は 1文字を返しますが、読み込みに失敗したときは EOF を返します。
EOF はたいてい負の値なので、受け取り側は int が安心です。
getchar と EOF の関係
| 項目 | 内容 |
|---|---|
| getchar の戻り値型 | int |
| 返ってくる値 | 読んだ文字のコード、または EOF |
| EOF | 入力終了やエラーを表す特別な値(多くは負) |
| 受け取り変数 | int ch; が安全 |
サンプルプログラム
入力した1文字が数字なら “数値として” 表示するシンプル例に変更します(メッセージも別の日本語)。
例:数字文字なら数値にして表示、数字以外は文字コードを表示
プロジェクト名:chap8-13-1 ソースファイル名:chap8-13-1.c
#include <stdio.h>
int main(void)
{
int ch;
puts("1文字入力してください(終了は Ctrl+D または Ctrl+Z)。");
while ((ch = getchar()) != EOF) {
if (ch == '\n')
continue;
if ('0' <= ch && ch <= '9') {
printf("数字文字です:%d\n", ch - '0');
} else {
printf("数字ではありません:文字=%c コード=%d\n", ch, ch);
}
}
return 0;
}実行例(イメージ)
1文字入力してください(終了は Ctrl+D または Ctrl+Z)。
7
数字文字です:7
A
数字ではありません:文字=A コード=65なぜ ch - '0' で 0〜9 になるの?
ここが一番おいしいところです。
文字から添字や数値を作る仕組み
'0' を基準にすると…
'0' - '0' = 0
'5' - '0' = 5
'9' - '0' = 9
説明
'0'〜'9' が連続して増える(1ずつ増える)なら、差を取れば 0〜9 が作れます。
これが「数字文字カウント」や「文字→数値変換」で大活躍します。
switch(数値ベタ書き)→ if(数値)→ if(文字)へ:可搬性の進化
A/B/C の比較(可搬性と読みやすさ)
| 方式 | 例 | 良いところ | 弱点 |
|---|---|---|---|
| A:switch(数値コード) | case 48, 49… | 仕組みは分かりやすい | 48 という値に依存しやすい |
| B:if(数値範囲) | ch >= 48 && ch <= 57 | 短い | 48〜57 に依存しやすい |
| C:if(文字で判定) | ch >= '0' && ch <= '9' | 読みやすい、移植に強い | 特になし(推奨) |
表の説明
48 や 57 を直接書くと、「その環境の文字コードでたまたまそう」という前提が入りやすくなります。
一方で '0' と '9' を使う書き方は、C言語が保証しているルール(後述)に乗れるので強いです。
重要:C言語が保証してくれるルール
環境によって '0' の数値(コード)そのものは違う可能性があります。
でも C言語では、次が保証されています。
保証される関係
'0','1',…,'9' は 1ずつ増える並び
だから '5' - '0' は必ず 5
説明
ここが「可搬性の核心」です。
'0' が 48 かどうかは環境で違っても、'0' からの差分で 0〜9 が作れることが保証されています。
数字文字カウントが短く書ける理由
数字文字の出現回数を数えるなら、switch で10個 case を並べるより、こう書けます。
数字文字カウントの最短パターン
| やること | 書き方 |
|---|---|
| 数字か判定 | if ('0' <= ch && ch <= '9') |
| 対応する箱を増やす | cnt[ch - '0']++ |
表の説明
cnt の添字が 0〜9 なので、'0' を引いて 0〜9 に変換すればピッタリ対応します。
登場する命令・構文の書式と役割
getchar の書式
int getchar(void);
何をする?
標準入力から次の1文字を読み、読めた文字のコードを返します。入力終了やエラーでは EOF を返します。
puts の書式
int puts(const char *s);
何をする?
文字列を標準出力へ表示し、最後に改行を付けます。
printf の書式
int printf(const char *format, ...);
何をする?
書式に従って表示します。%c は文字、%d は整数を表示します。
while の書式(EOFまで読む定番)
while ((ch = getchar()) != EOF) {
...
}
何をする?
1文字ずつ読み、EOF が来るまで繰り返します。
if の書式(数字判定)
if ('0' <= ch && ch <= '9') {
...
}
何をする?
数字文字のときだけ処理する安全装置です。
まとめ:文字の '0' と数値の 0 を分けられると強い
- 文字は整数(文字コード)として扱われる。
- '0' は 0 ではなく、文字コード上の値(例:48)
- getchar の戻り値は EOF も扱うので int で受ける。
- 数字文字は '0'〜'9' が連続して増えるのが保証されている。
- だから ch - '0' で 0〜9 を安全に作れて、カウントや変換が簡潔になる。