
C言語入門|文字列の終わりはどう決まるのか
前の記事で、
「C言語の文字列は char 配列である」
という事実を確認しました。
でも、ここで誰もが一度は立ち止まります。
文字列って、
どこまでが文字列なんだろう?
これはとても大事な疑問です。
実はこの問いに答えられるかどうかで、
C言語で文字列を 安全に扱えるかどうか が決まります。
メモリ上の文字列をもう一度眺めてみよう
次のような文字列変数を思い出してください。
typedef char String[1024];
String str = "hello";メモリ上では、次のような状態が想像できます。
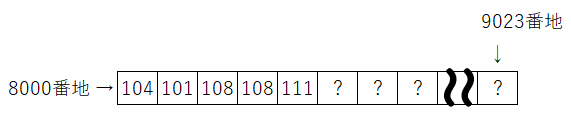
ここで、素朴な疑問が生まれます。
文字なのに、なぜ数字が入っているの?
h が 104、e が 101……
数字が並んでいて、少し違和感がありますよね。
でも、これはまったく自然なことです。
C言語では、
- 文字も
- 数値も
すべて「数値」としてメモリに格納されます。
文字は単に、
文字コードという数値で表現されている
だけなのです。
本当に重要な疑問
ここからが、本題です。
コードを実行すると、画面には
helloと表示されます。
でも、冷静に考えるとおかしくありませんか?
重要な疑問
なぜ、1024文字分のメモリ領域のうち、
先頭の5文字分しか表示されないのだろう?
変数 str は、
ただの「1024バイトのメモリ空間」です。
その先頭に hello が入っているだけで、
後ろの 1019 バイトにも、
何らかの値が入っているはずです。
メモリの中身をのぞいてみる
そこで、文字列として表示するだけでなく、
中身を数値として確認してみましょう。
サンプルプログラム
プロジェクト名:11-2-1 ソースファイル名: sample11-2-1.c
#include <stdio.h>
typedef char String[1024];
int main(void)
{
String str = "hello";
printf("%s\n", str);
for (int i = 0; i < 10; i++) {
printf("%d, ", str[i]);
}
printf("\n");
return 0;
}実行結果
hello
104, 101, 108, 108, 111, 0, 0, 0, 0, 0,見えてきた「決定的な違い」
結果をよく見てください。
- h e l l o の5文字分のあと
- 0 が並んでいる
ここに、
C言語の文字列の正体が隠れています。
文字列の終わりを示す特別な値
C言語の文字列には、
長さ情報は一切含まれていません。
代わりに使われているのが、
値が 0 の文字(ヌル文字)
です。
この 0 は、
- 数値としては 0
- 文字としては「何も表示しない特別な文字」
であり、
文字列の終わりを示す目印 として使われます。
printf は何を見て止まっているのか
printf は、
文字列を表示するときに、
- 先頭から順に文字を読み出す。
- 値が 0 の文字に出会ったら
- 「ここで文字列は終わり」と判断する。
というルールで動いています。
だから、
- hello の後ろに
- いくらデータがあっても
0 が出た時点で表示が止まる のです。
では、途中に別の値を入れたら?
ここで、少し意地悪な実験をしてみましょう。
次の1行を、文字列代入の直後に追加します。
str[9] = 67; // 'C'つまり、
10文字目に「C」を書き込む、という操作です。
実行結果
hello
104, 101, 108, 108, 111, 0, 0, 0, 0, 67,「あれ?」
「helloC」と表示されると思いませんでしたか?
なぜ helloC にならないのか
理由は、とてもシンプルです。
- hello の直後、5文字目の次
- すでに 0 が置かれている
printf は、
0 を見つけた時点で
文字列の終わりだと判断
します。
そのため、
- 9文字目に 67 があっても
- そこまでたどり着くことはありません
ここで押さえておくべき核心
ここまでで、
C言語の文字列について、
とても重要な事実が見えてきました。
C言語の文字列の本質
- 文字列は char 配列
- 長さ情報は持たない
- 値 0 が「終わり」を示す唯一の手がかり
この 0 を 終端文字(ヌル終端) と呼びます。
この仕組みが「便利」で「怖い」理由
この仕組みのおかげで、
- どんな長さの文字列でも
- 同じ関数で扱える
という便利さが生まれました。
一方で、
- 0 を入れ忘れる。
- 0 を壊してしまう。
- 配列の範囲を越えて探し続ける。
と、
第10章で学んだ オーバーラン に
一気につながります。
次の記事で学ぶこと
次は、
- 終端文字はいつ、どこで入るのか
- 自分で文字列を作るとき、何に注意すべきか
- なぜ文字列操作関数は危険なのか
を、さらに深く掘り下げていきます。
ここを理解できると、
C言語の文字列が急に怖くなくなる はずです。