
C言語入門|配列と構造体に共通する禁止事項
ここまで配列や構造体について、
いろいろな使い方を学んできましたね。
そこで、多くの人がふと、こんな疑問を口にします。
「……あれ?
結局、まるごと扱う操作って、全部ダメなんですか?」
はい、平たく言えば そういうこと になります。
この章では、配列と構造体に共通する
「やってはいけない操作」 をまとめて整理していきます。
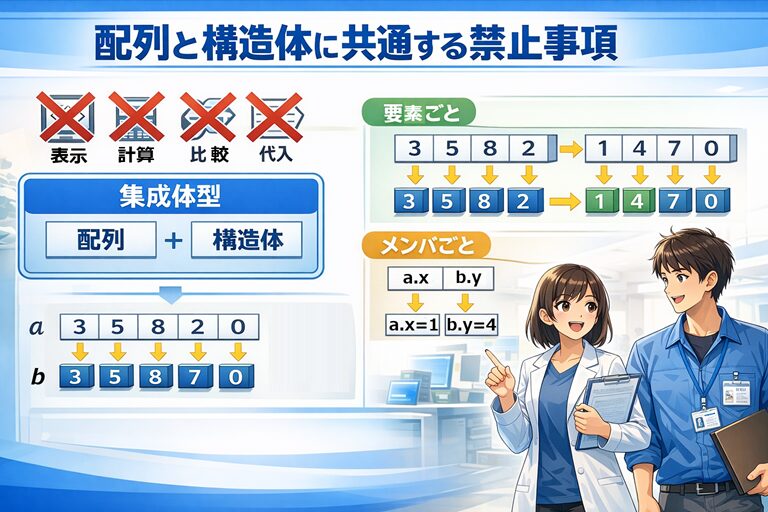
集成体型は「まるごと操作」するものではない
配列型や構造体型は、どちらも 集成体型 に分類されます。
集成体型とは、
- 複数のデータを
- 1つのまとまりとして扱うための型
でしたね。
ただし、ここで大切なのは、
まとめて管理できる
=
まとめて操作できる
では ない という点です。
そもそも命令や演算子は何のためのもの?
printf や +、==、= といった命令や演算子は、
もともと
- 数値1つ
- 文字1つ
といった 単一の値 を扱うために設計されています。
そのため、複数の値を内部に持つ集成体型に対して
無理に使おうとすると、
想定外の振る舞い を引き起こします。
配列と構造体で起きる問題の違い
構造体の場合は、
ダメな操作をすると コンパイルエラー になりやすく、
比較的気づきやすいです。
一方、配列はもっと厄介です。
- コンパイルは通る
- 実行もできる
- でも結果が意味不明
という状態になりやすいのです。
これが、配列が
「使うのは簡単、正しく使うのは難しい」
と言われる理由です。
禁止事項を表でまとめて確認しよう
ここで、基本型・構造体型・配列型に対して
どんな操作ができて、どんな操作が危険なのかを
表で整理してみましょう。
| 操作 | 表示 printf() など | 計算 + - * など | 比較 == != など | 代入(コピー) = |
|---|---|---|---|---|
| 基本型 | ○ | ○ | ○ | ○ |
| 構造体型 | ○ | × | ○ | ○ |
| 配列型 | ☠ | ☠ | ☠ | ☠ |
記号の意味
- ○:問題なく使用できる
- ×:コンパイルエラーになる
- ☠:コンパイルは通るが、実行時に異常動作の恐れあり
配列が「全部☠」なのはなぜ?
表を見て、思わずこう言いたくなりますよね。
「配列、全部ダメじゃないですか!」
はい、その感覚は正しいです 😊
しかも配列の場合、
エラーにならないのが一番怖いポイント です。
よくある危険な例
int a[] = {1, 2, 3};
int b[] = {1, 2, 3};
if (a == b) {
printf("同じ配列です\n");
}このコードはコンパイルできますが、
比較しているのは 中身ではなく先頭要素の位置 です。
結果が正しいかどうかは、
まったく保証されません。
構造体も「万能」ではない
構造体は配列より安全に見えますが、
やはり万能ではありません。
struct Point {
int x;
int y;
};
struct Point p1 = {3, 4};
struct Point p2 = {5, 6};
printf("%d\n", p1); // NG構造体をそのまま表示しようとすると、
コンパイルエラーになります。
これは、
- printf が単一の値を想定している。
- 構造体は複数の値を持っている。
という設計のズレが原因です。
正しい考え方は「要素単位・メンバ単位」
集成体型を扱うときの基本姿勢は、とてもシンプルです。
- 配列 → 要素ごとに扱う
- 構造体 → メンバごとに扱う
配列の正しい扱い方
for (int i = 0; i < 3; i++) {
printf("%d\n", a[i]);
}構造体の正しい扱い方
printf("x=%d y=%d\n", p1.x, p1.y);「まるごと」ではなく
「中身に分解して」操作する。
これが鉄則です。
集成体型に対するNG発想
この章で、ぜひ捨ててほしい発想があります。
集成体型に、まるごと何かをさせよう
この考え方を持っている限り、
配列や構造体では必ずつまずきます。
代わりに、こう考えてください。
集成体型は、
中身を取り出して使うための入れ物
この意識に切り替えるだけで、
コードの安全性と読みやすさが一気に上がります。
まとめ:集成体型は「分解して使う」
最後に、この節のポイントをまとめます。
- 配列と構造体は集成体型
- 集成体型は単一の値ではない
- 表示・計算・比較・代入は原則NG
- 操作は必ず中身に対して行う
配列は特に、
- エラーにならない
- でも危険
という特徴を持っています。
だからこそ、
常に注意点を頭の片隅に置いて使う
それが、C言語エンジニアとしての大切な姿勢です 😊