
C言語入門|char型とは?1文字を格納するしくみと日本語が入らない理由
C言語で文字を扱うときに登場する基本の型が char型(キャラ型/チャー型) です。
「1文字を保存する箱」として使われる、とても重要で便利なデータ型なんですね😊
でも実は、
char型には “半角英数字や記号しか入らない”
という大きな特徴があります。
ここでは、「なぜ1文字しか入らないの?」「なぜ日本語が入らないの?」を、しくみから優しく解説していきます✨
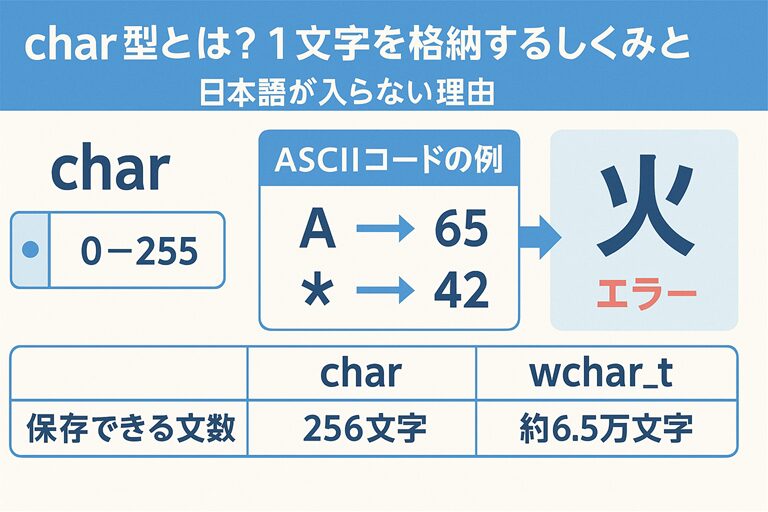
🧱 文字は数値として保存されているって知ってた?(文字コードの仕組み)
コンピュータは文字をそのまま理解できないので、
文字 → 数値(文字コード) に変換して保存しています。
例として、有名な ASCII コードではこんな対応になっています👇
| 文字 | 割り当てられた数値 |
|---|---|
| A | 65 |
| * | 42 |
| _ | 95 |
| { | 123 |
つまり、
'C' を代入する → 実際には 67 が保存される
ということです。
🧪 char型のサンプル
プロジェクト名:2-7-1 ソースファイル名: sample2-7-1.c
#include <stdio.h>
int main(void)
{
char grade; // 成績ランク(1文字)
grade = 'B'; // 実際には 66 がメモリに入る
printf("評価ランク: %c\n", grade);
printf("内部コード: %d\n", grade);
return 0;
}🔍 命令の説明
printf
- 書式:printf("書式文字列", 値);
- %c → 文字として表示
- %d → 数値(文字コード)として表示
🧩 なぜ char は “1文字だけ” しか保存できないの?
char型は 1バイト(8ビット) のデータしか保存できません。
つまり、
- 保存できる値の種類は 0〜255 の 256種類
- そのため入れられる文字も 256種類まで
ASCII は128種類、拡張ASCIIは256種類なので、
半角文字だけなら char で十分 というわけです。
図で表すとこうなります👇

😢 日本語(全角文字)が入らない理由
日本語は「漢字・ひらがな・カタカナ」など膨大な種類があります。
JIS・Unicode では 何千〜数万文字 が収録されています。
▶ char の 256種類では到底足りません!
たとえばこのコード
char element;
element = '火';これは char に収まらないため コンパイルエラー になります。
日本語を扱う場合は もっと大きい型、例えば wchar_t が必要になります。
🧠 日本語の文字コードはどうなってるの?
ASCII(半角英数字) → 1バイトでOK(256種類以内)
日本語(漢字・ひらがな)→ 数千〜数万文字(1バイトでは絶対足りない)
なので char 型には入りません。
📚 char型は文字型であり“整数型”でもある
char型は中身が数値なので、本質的には 整数型 の仲間です。
| 型名 | 説明 |
|---|---|
| char | 1バイトの整数型。結果として文字も扱える。 |
つまり、
char letter = 'C';は実際には
letter = 67;と同じ意味なんですね😊
🎉 あなたはチャー派?キャラ派?
char の読み方は実は人によってバラバラ。
- 「チャー型」
- 「キャラ型」
- 「キャラクター型」
どれも一般的で、正解はありません😊